>Hi !
>
>Thank you for your elaborate reply!
>I'm afraid that the point I was trying to make is getting lost in the
>discussion, so I do not answer to all your statements point by point but try
>to rephrase the discussion.
>
>The starting point was whether the "proof" layer needs to be exclusively
>based on unified (FO)logic - something I saw being implied by your objection
>to the direct connection between the "Rule/RIF" and "Proof Layer"in the
>layer stack - bypassing the unified logic. Considering that I understand
>the proof layer to contain *all* SWeb reasoning I feared that this also
>meant that the proof layer must exclusively rely on OWL deduction -
>something that struck me as utterly unrealistic (and that's also where the
>long list of "muddled, unrelated topics" came from - things beyond OWL
>deduction I imagine happening in the proof layer). (01)
We were clearly not understanding one another. By
no means is OWL the last word in Web logics. The
only plausible candidates for a 'unified Web
logic' so far are some version of FOL, preferably
with a very forgiving syntax, like Common Logic,
or some extension of this which allows for a
degree of reflexive self-description, such as IKL
or (full) N3. But it is probably too early to
standardize such an extension right now. (02)
>Now I understood your reply as meaning that for you the OWL semantics are a
>kind of minimalistic, basic semantics; that people are free to use other
>kinds of assumptions and reasoning on top, kind of at their own risk. (03)
Well, say RDF for the minimal, basic, then yes.
And the 'own risk' needs to be clarified. People
are, and always will be, free to take information
on the Web and use it in any way they please,
drawing conclusions at their own risk. The issue
comes when they publish those conclusions for
others to use, and whether that 'risk' is then as
it were transmitted to others without their
knowing about it. That seems unreasonable. The
point of cleaving to monotonicity in the
semantics of a global formalism for
intercommunication is to ensure that what is
meant by the publication of some content is
exactly what it available to the reader of that
content, and that this transmitted meaning is
sanctioned by the network for use with other
transmitted information. The semantics of this
global transmission of content has to be
monotonic because there is no way the publisher
can forsee or control what other information will
be added to the published content before it is
used by a reader. So all assumptions on which the
meaning depends should be made explicit in the
publication itself. Which is just another way of
saying that the semantics of the publication
language are monotonic. (04)
> Also
>that you imagine this to be mainly logical deduction (05)
Yes, but for essentially pragmatic reasons. (06)
>and that many of the
>features under discussion to be used there are just not good enough
>understood to be standartized yet. (07)
No. Some of them are quite well understood, but I
don't think are relevant to the semantics of the
intercommunication language (abduction,
induction). Some of them are well understood and
it is clear should be deliberately excluded from
this language (nonmonotonic entailments). Others
are not yet well enough understood. And still
others are likely to be useful but do not, contra
frequent claims, require going beyond FOL
(contexts, time-stamping, modalities). (08)
>Then, to come back to the starting point, we do not have a clear picture of
>everything happening in the proof layer - and we could imagine things in the
>proof layer not (exclusively) being based on OWL semantics. But then I don't
>get your problem with the "rule-layer <-> proof-layer kink in the layer
>cake. Yes - one unified logic has a certain beauty to it (09)
Its not a question of beauty, but of an essential
semantic simplicity. And this is subject to
rigorous proof, cf. the (010)
>- but there is no
>problem with some SWeb agent taking some statements, using some ontology to
>derive some more and then using some PROLOG rules and a query to get its
>final result - or is there? (011)
Well, I would not want to lay down rules about
what agents can or cannot DO, and none of the
SWeb specs do lay down any such rules (we were
very careful on this point.) However, it would be
a very dangerous process to use on an open
network, since Prolog semantics is based on a
closed world. The chances of getting incorrect
results are very high, unless the agent somehow
knows that it is dealing with a closed world
situation. Now, how can it know that, in general?
If there is some way to communicate this in the
logical language, then yes, of course Prolog
techniques should be used wherever they can be.
But if the closed-world assumptions are made
explicit, the overall logic is still monotonic. (012)
>Yes, depending on the order in which i do this
>and details of the formalisms the conclusions may not be correct FOL
>inferences (013)
Actually, in every case Ive seen, they are always
first-order enthymemes. That is, they are valid
first-order (or close to first-order: sometimes
one needs a little recursion added) inferences
from a slightly larger set of assumptions, in
which for example the unique name assumption is
made explicit, or the universal statement
justifying NAF is made explicit. Making these
assumptions explicit is exactly what we need a
fully adequate logic. (014)
>- but then, didn't we agree that lots of the things in the proof
>layer won't be? To me it seems that the moment you are insisting on the
>proof layer to be based exclusively on the Unified Logic (equated with FOL
>semantics) your minimalistic semantics that keeps all possiblities open,
>suddenly excludes quite a lot (the LP community for one). (015)
Not if it is all done right. But I agree we need
an unusual logic to do this all in properly. It
is interesting that a relatively small FOL
extension, what amounts in effect to a zero-order
comprehension principle, allows IKL to express a
wide variety of what are traditionally thought of
as 'nonmonotonic' inferences all in a strictly
monotonic framework, see (016)
http://ontolog.cim3.net/file/resource/presentation/PatHayes_20061026/OntologyWorkshopSlides.html (017)
slide 28 (018)
>and to answer one more point:
>>I think you are muddling the chaotic state of the
>>Web with the idea that information on the Web
>>must be somehow faulty or inconsistent, [...]
>> Tim B-L has some interesting musings
>> on this topic, by the way.
>
>It is indeed my conviction that information on the web will always be faulty
>and inconsistent (019)
It will be *globally* inconsistent, yes. So what?
Nobody plans to download every Web ontology into
one gigantic database. And the key issue for the
global semantics is that it allow agents to
reliably detect such inconsistencies, which is
another argument for a classical model theory. (020)
>- I fail to see any argument to the contrary; even cyc
>failed to build one consistent world-kb - and this is still a relatively
>small kb, build under very controlled circumstances by very skilled people
>with largely aligned goals and relatively similar cultural background and
>education. Wikipedia is permanently faulty and inconsistent - as is the
>Encyclopedia Britannica or every humans knowledge. But I'll read up on Tim
>B-Ls musings on the topic - I ass (021)
No, he has quite a lot of online technical
bloggings which discuss this and other related
issues. They are all on the W3C site somewhere. (022)
Pat (023)
>
>cu
>
>
>valentin
>
>--
>email: zacharias@xxxxxx
>phone: +49-721-9654-806
>fax : +49-721-9654-807
>http://www.vzach.de/blog
>
>=======================================================================
>FZI Forschungszentrum Informatik an der Universit�t Karlsruhe (TH)
>Haid-und-Neu-Str. 10-14, 76131 Deutschland, http://www.fzi.de
>SdbR, Az: 14-0563.1 Regierungspr�sidium Karlsruhe
>Vorstand: R�diger Dillmann, Michael Flor, Jivka Ovtcharova, Rudi Studer
>Vorsitzender des Kuratoriums: Ministerialdirigent G�nther Le�nerkraus
>=======================================================================
>
>
>> -----Urspr�ngliche Nachricht-----
>> Von: Pat Hayes [mailto:phayes@xxxxxxx]
>> Gesendet: Freitag, 3. August 2007 18:00
>> An: Valentin Zacharias
>> Cc: Pat Hayes; John F. Sowa; [ontolog-forum]; Ivan Herman; Juan
>> Sequeda; SW-forum list
>> Betreff: Re: AW: [ontolog-forum] Current Semantic Web Layer Cake
>> Wichtigkeit: Hoch
>>
>> >Hi!
>> >
>> >Pat Hayes said:
>> >[...]
>> >>I am slightly concerned that this peculiar kink in the layer
>> >>cake has been put there deliberately to make it possible to do an
>> >>end-run around a unifying logic. Which when one takes into account
>> >>the whole point of "Unifying", would IMO be a pity.
>> >[...]
>> >
>> >I can understand that people insist on Semantic Web languages to have
>> a
>> >formal, or even a model theoretic semantic.
>>
>> "even" ?? But never mind, let us proceed.
>>
>> >What I don't get is that you
>> >(and John F. Sowa in other emails) seem to insist that this must be
>> classic,
>> >FOL like, monotonic semantic and that all formalisms with different
>> >semantics (or kinds of reasonings) have no place in the Semantic Web.
>>
>> You draw too rapid a conclusion. I don't think
>> that nonclassical logics have NO place on the
>> SWeb. But one has to draw a distinction between
>> 'useful somewhere' and 'suitable as a basis for
>> global interoperability'. All of the Sweb
>> standards defined so far (RDF, OWL, SPARQL) are
>> intended for use at the 'top level' of the SWeb,
>> to be suitable for use for communication between
>> systems located anywhere on the Web, using data
>> which may come from many sources, be archived or
>> not, etc.. Under these assumptions one can make a
>> very good argument that the basic semantics of
>> such interoperation languages must be monotonic,
>> context-independent: because, in essence, the
>> context in which it was published is no longer
>> available at the point of use. See
>> http://www.ihmc.us:16080/users/phayes/IKL/GUIDE/GUIDE.html#LogicForInt
>> and
>> http://ontolog.cim3.net/file/resource/presentation/PatHayes_20061026/On
>> tologyWorkshopSlides.html
>> especially slides 4-6
>>
>> >To me it seems obvious that these semantics cannot be the exclusive
>> basis
>> >for reasoning on a global,open knowledge based system
>>
>> Not exclusive, but for the main basis, I think
>> one cannot really go much beyond classical
>> semantics, precisely because they are so weak.
>> All other semantics make some implicit assumption
>> which is not globally valid.
>>
>> >, because:
>> >
>> >1) These semantics do not consider
>>
>> True. But the fact that they do not consider
>> certain topics does not mean that those topics
>> are incompatible with them, or are ruled out of
>> consideration for ever. And one should not
>> usually seek to standardize topics which are
>> still the subject of active research discussion
>> and have no body of established practice to
>> appeal to.
>>
>> >quantitative aspects (e.g. 5000 locations
>> >state that a(mike), only 2 state that b(mike)), don't allow for closed
>> world
>> >reasoning
>>
>> They ALLOW for it, but do not mandate it during
>> global information exchange, for the very good
>> reason that the Web is not a closed world. CW
>> reasoning is simply invalid when applied to the
>> entire Web. The unique name assumption is false;
>> failure is not negation; etc..
>>
>> >, do not consider trust, require very strict global consistency....
>>
>> Again, they do not REQUIRE global consistency, or
>> indeed even local consistency. They simply, as
>> classical semantics always do, give up when faced
>> with inconsistency. They do not deal adequately
>> with it, true: there is as yet no globally
>> acceptable standard way to deal with it. One has
>> to deal with each case on its merits. The fact
>> that the standards do not deal with these issues
>> is not a message that they are irrelevant or
>> prohibited, only that they are still the subject
>> of research and to some extent emergent future
>> practice. We will have to wait and see what
>> happens, before trying to impose a standard here.
> >
>> >Because of this they cannot reflect the intuitions and expectations of
> > >humans about what should be concluded from a set of statements as
>> unordered
>> >and ungoverned as the web.
>>
>> I think you are muddling the chaotic state of the
>> Web with the idea that information on the Web
>> must be somehow faulty or inconsistent, or that
>> people use (or perhaps should use) a different
>> kind of reasoning when faced with a large messy
>> dataset. I don't think this is a valid
>> conclusion. Tim B-L has some interesting musings
>> on this topic, by the way.
>>
>> > Hence actual applications will in any case use
>> >other notions of truth and entailment (or come to conclusions that are
>> not
>> >accepted by the users and probably not very useful).*
>>
>> What makes you assume that contexts and
>> uncertainty reasoning are excluded by a classical
>> semantics?
>>
>> >2) Should we really ever get reasoning semantic web agents, isn't it
>> >preposterous to assume that will rely exclusively on logical
>> deduction?
>>
>> Perhaps not exclusively, but I think the main
>> basic inference mode will be deductive, yes. That
>> has certainly been the case so far in most
>> applications. Classical deduction can, with
>> current technology, be usefully applied to
>> datasets containing many millions of facts.
>>
>> >- Why
>> >not induction, abduction, analog reasoning, data mining, nlp, ir,
>> simulation
>>
>> You are muddling together a host of unrelated
>> topics here. Induction and abduction are not even
>> logical forms of entailment, and are both
>> consistent with a classical notion of truth.
>> Analogical (aka metaphorical) reasoning turns out
>> in most application I have seen to be a
>> pattern-matching process on structures which
>> themselves have a classical semantics (and in
>> many cases are expressions in FOL.) Data mining
>> is a separate topic which is not required to be
>> nonclassical (we have used datamining software
>> with OWL, for example). NLP systems often use
>> deductive reasoning. And so on. Yes, Im sure all
>> these and more will be used by SWeb technologies
>> of one kind or another. None of that however is a
>> good reason for basing the global notations of
>> information exchange on anything more elaborate
>> than simple model theory.
>>
>> >... Doesn't this mean that in any case there will never be a complete
>> >mapping between the "proof" and the "logic" layer (as currently
>> envisioned)?
>> >I also don't see how any kind of inference can be done on web scale
>> without
>> >a large (essentially heuristic) information retrieval component trying
>> to
>> >get the relevant statements (considering what we know about the
>> complexity
>> >of inference algorithms) - again breaking the direct logic layer-proof
>> layer
>> >mapping.
>> >
>> >my opinion in short: we don't have any semantics that covers
>> everything that
>> >is needed (and I don't even see one at the horizon), hence we should
>> not
>> >stifle innovation by insisting on one thats clearly inadequate for the
>> task
>> >at hand.
>>
>> I agree with your premis, but draw a totally
>> different conclusion. As we MUST have an
>> interoperability standard to even get the SWeb
>> off the ground, we should choose one that
>> restricts innovation as little as possible: the
>> most bland, vanilla, uncontroversial basis that
>> everyone can accept and build on. What semantic
>> framework would you suggest be adopted as the
>> basis for SWeb information exchange?
>>
>> (BTW, I find your criticism kind of ironic, since
>> we have been the subject of torrents of criticism
>> for making the RDF and OWL-Full semantics too
>> 'non-standard' by not basing it strictly on
>> textbook model theory.)
>>
>> Pat
>>
>>
>>
>> >
>> >
>> >cu
>> >
>> >valentin
>> >
>> >
>> >*: given the large amount of research into things like
>> circumscription,
>> >uncertainty reasoning, rdf/dl+contexts etc. I was under the impression
>> that
>> >this is a SW-community mainstream position.
>> >
>> >--
>> >email: zacharias@xxxxxx
>> >phone: +49-721-9654-806
>> >fax : +49-721-9654-807
>> >http://www.vzach.de/blog
>> >
>> >======================================================================
> > =
>> >FZI Forschungszentrum Informatik an der Universit�t Karlsruhe (TH)
>> >Haid-und-Neu-Str. 10-14, 76131 Deutschland, http://www.fzi.de
> > >SdbR, Az: 14-0563.1 Regierungspr�sidium Karlsruhe
>> >Vorstand: R�diger Dillmann, Michael Flor, Jivka Ovtcharova, Rudi
>> Studer
>> >Vorsitzender des Kuratoriums: Ministerialdirigent G�nther Le�nerkraus
>> >======================================================================
>> =
>> >
>> >> -----Urspr�ngliche Nachricht-----
>> >> Von: semantic-web-request@xxxxxx [mailto:semantic-web-
>> request@xxxxxx]
>> >> Im Auftrag von Pat Hayes
>> >> Gesendet: Dienstag, 31. Juli 2007 17:20
>> >> An: John F. Sowa
>> >> Cc: [ontolog-forum]; Ivan Herman; Juan Sequeda; SW-forum list;
>> >> semantic_web@xxxxxxxxxxxxxxxx
>> >> Betreff: Re: [ontolog-forum] Current Semantic Web Layer Cake
>> >>
>> >>
>> >> >Pat,
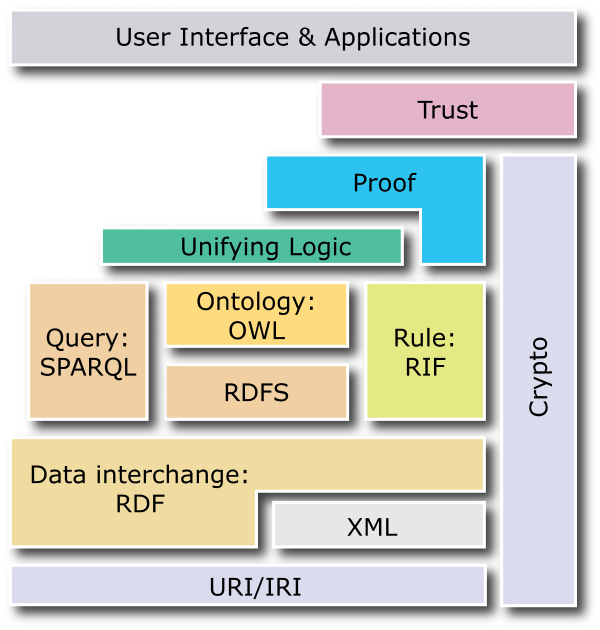
>> >> >
>> >> >I agree that the proof box is misplaced, but I think
>> > > >that the major problem is that the logic box is not
>> >> >correctly positioned.
>> >> >
>> >> >> http://www.w3.org/2007/03/layerCake.png
>> >> >
>> >> >PH> Hmm, I wonder why the 'Proof' Tetris piece has
>> >> >> a connection to Rule without going through Unifying
>> >> >> Logic. That seems like a very bad decision to me
>> >> >
>> >> >Unifying Logic is the framework that includes the others
>> >> >as subsets: RDF, RDF-S, Rule RIF, OWL, and SPARQL.
>> >> >
>> >> >Each of these subsets is tailored for a specific kind of
>> >> >inference engine and/or a specific range of uses. What
>> >> >unifies them is the common model-theoretic semantics.
>> >> >That semantics enables all of them to interoperate on
>> >> >shared data and produce consistent results.
>> >>
>> >> Thats what I would expect, yes. And I know the overall picture.
>> What
>> >> surprised me was the fact that there seems to be a special
>> >> short-circuit allowing Rules to connect to Proof without taking the
>> >> Logic into account. Which in turn suggests a special dispensation
>> for
>> >> Rules to avoid having to have a common semantics with everything
>> >> else. As I know there are, as the popular media says, Powerful
>> Forces
>> >> in the Rules meta-community which would approve of short-circuiting
>> >> conventional semantics altogether in favor of, say, some version of
>> >> Prolog, I am slightly concerned that this peculiar kink in the
>> layer
>> >> cake has been put there deliberately to make it possible to do an
>> >> end-run around a unifying logic. Which when one takes into account
>> >> the whole point of "Unifying", would IMO be a pity.
>> >>
>> >> Pat
>> >>
>> >> >
>> >> >My suggestion would be to draw the Unifying Logic box as
>> >> >a large container that includes all the others inside:
>> >> >RDF, RDF-S, Rule RIF, OWL, and SPARQL.
>> >>
>> >> The layer-cake display has become a kind of W3C icon now.
>> >>
>> >>
>> >> --
>> >> -------------------------------------------------------------------
>> --
>> >> IHMC (850)434 8903 or (650)494 3973 home
>> >> 40 South Alcaniz St. (850)202 4416 office
>> >> Pensacola (850)202 4440 fax
>> >> FL 32502 (850)291 0667 cell
>> >> phayesAT-SIGNihmc.us http://www.ihmc.us/users/phayes
>> >>
>>
>>
>> --
>> ---------------------------------------------------------------------
>> IHMC (850)434 8903 or (650)494 3973 home
>> 40 South Alcaniz St. (850)202 4416 office
>> Pensacola (850)202 4440 fax
>> FL 32502 (850)291 0667 cell
>> phayesAT-SIGNihmc.us http://www.ihmc.us/users/phayes (024)
--
---------------------------------------------------------------------
IHMC (850)434 8903 or (650)494 3973 home
40 South Alcaniz St. (850)202 4416 office
Pensacola (850)202 4440 fax
FL 32502 (850)291 0667 cell
phayesAT-SIGNihmc.us http://www.ihmc.us/users/phayes (025)
_________________________________________________________________
Message Archives: http://ontolog.cim3.net/forum/ontolog-forum/
Subscribe/Config: http://ontolog.cim3.net/mailman/listinfo/ontolog-forum/
Unsubscribe: mailto:ontolog-forum-leave@xxxxxxxxxxxxxxxx
Shared Files: http://ontolog.cim3.net/file/
Community Wiki: http://ontolog.cim3.net/wiki/
To Post: mailto:ontolog-forum@xxxxxxxxxxxxxxxx (026)
|
{kind=link}