Hi Doug, John, Pavithra in that order of your posts, et al,
I seem to have a talent for underspecifying my visual descriptions. Let
me use a drawing to better, more precisely state the situation in words that
map onto the figure. Consider three symbol tables, each allocating an
identifier in one dimension in the order of arrival of that UNIQUE integer
arrival identifier, which can occur multiple times in a database. Here is
a figure which kinda illustrates what I am visualizing:
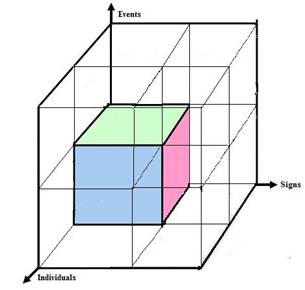
Sign IDs start begin allocated from the origin, starting at ID=1 for
the first sign, and incrementing the symbol ID (2,3, .. Ns) for signs, one at a
time upon encountering them. Those signs, let me further constrain, are
allocated IDs in one pass through a text file which has well formed statements
of the vocabulary in which a sign, first encountered, gets assigned a new ID. If
that sign is encountered again later in the text file, the symbol table pairs
it with its very first ID for the rest of the pass through the text.
Similarly, the events are IDed in order of their being encountered in
the same text file during one pass scan. They use (conceptually) a
distinct symbol table, and some of the events may be named identically with the
signs, so that “write” can be a sign or an event since it is in
reality naming two different kinds of things. That set of events is on
the Y axis above, and are recognized as events, not signs, based on the syntax
of the text tokens to be an event, not a sign.
On the third axis, Individuals - the constant <object/thing/designating
phrase..> IDs allocated in arrival order by a third conceptual symbol table -
which appears in the expressions for event statements (e.g. sentences) that
identify slot fillers for specific events, some of which may be the same KIND
of sentences (Michael rowed the boat ashore. Michael threw a stone into
the sea. Janet hurled the sandwich onto the wall. …) based on a
similarity measure of syntax TBD.
I may STILL not be stating this in a recognizable way (your
forebearance is appreciated), but what I am trying to say is that the two independent
axes (Event IDs and sign IDs) which are arbitrarily defined as pattern types,
one type for each position (ID) on these two axes.
The third axis is dependent on the pattern fillers which (glossed over
mostly, but please try to imagine what I am seeing) identify individual
designations (Michael, rowed, boat, ashore, threw, stone, sea, Janet, hurled,
sandwich, wall, …) each with a concept.
Later in the text, there are phrases which refer to Michael (The man,
he, the rower, the thrower, …) based on correlating event slot fillers to
identify which phrases refer to which individual. These phrases occupy
the intersections of the three axes.
=================== ====================
Now having constructed the cube above with that one pass scan of the
text, the next task is to sort each of the three axes, maintaining the
integrity of the cube elements so that they are maintained as the same
statements, just reordered into the cube so that they form a positionally.
Given two sortings, the one with the same event types occupying one
block of entries on the event axis is preferred. So perhaps the events of
a given type appear contiguously on the event ID axis, even though the ID
numbers are no longer in sequential order.
The result is a sorted version of the three D cube with a slice of a
specific event type (with many instances) are contiguous, the IDs appear almost
randomly placed in their value sequence along the event axis. Here is
another view of that cube after sorting:
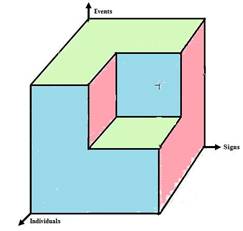
The gap at the highest gradient on all three axes indicates that there
are no statements which intersect the highest sort order sign with the highest
sort order event and the highest sort order individual.
Now by partitioning the image along each of the three axes, I can
organize the cube into six volumes, as shown below:
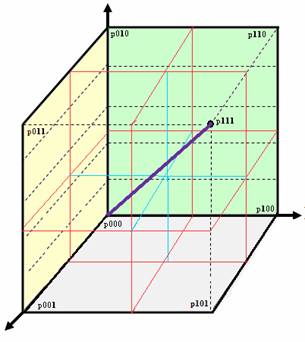
Note that the min and max points of the coordinate system on each axis
are subscripted in a Gray code way: p000 is the origin, p001, po10, p100, p111,
and so forth.
The purple line is, by construction describing a monotonically
increasing subscript for transitioning from the origin p000 to the highest enumerated
ID at p111.
I suggest that the ordering produced by this process can be searched by
three binary search iterators, each visiting only one axis. I also
suggest that the purple line can be viewed as an ordering of the three axes,
using gray code subscripts as above after the sort operation.
Having done all this, you may ask why bother? The construction I
am trying to organize (underspecified so far) is that a single binary search
can be used to find any statement(s) which unify with a query that may have
designations (event, individual, sign specifiers) which are combinations of
variables and constants.
Having constructed such, the ways in which unification of the query _expression_
with the cube contents appears to me to have a geometrical interpretation which
can be exploited to reduce the number of unifications which must be searched to
enumerate the possible resolutions for each potential unification, not fully
specified in some mappings, but fully specified to constants in others.
The goal is to find a way to partition the number of cases that have to
be fully evaluated to determine if there exists one or more unifications of the
query with the content.
Comments and questions, suggestions, appreciated.
Quizzically,
-Rich
Sincerely,
Rich Cooper
EnglishLogicKernel.com
Rich AT EnglishLogicKernel DOT com
9 4 9 \ 5 2 5 - 5 7 1 2
-----Original Message-----
From: ontolog-forum-bounces@xxxxxxxxxxxxxxxx
[mailto:ontolog-forum-bounces@xxxxxxxxxxxxxxxx] On Behalf Of Rich Cooper
Sent: Sunday, October 17, 2010 9:20 PM
To: '[ontolog-forum] '
Subject: Re: [ontolog-forum] Interpreting OWL
John, Pavithra, Doug et al,
A DAG is the normal, prototypical situation of databases then. That
constraint means that there is an ordering of the <relation>s on
one axis
and the <person/object/thing>s on another which would look like a
topographic map of a square of land. Specifically, the ordering
of
<relation>s by identifier associated with the temporal arrival
sequence of
the relation references in a <text/ontology/dictionary/lexicon>
in ascending
order by arrival, mapped against an ordering of <person/object/thing>s
in
ascending order of their own arrival. This is the structure of a
single
pass analysis from beginning to end of the model.
Is that intuition correct? I.e., a topographically level or
sloping model
of two <property/attribute/column>s in the value plane is ALWAYS
REALIZABLE
given the axes are ordered by arrival sequence in ascending order from
the
start (origin) of the <text/ontology/dictionary/lexicon> being
scanned in
one pass?
Queriously,
-Rich
Sincerely,
Rich Cooper
EnglishLogicKernel.com
Rich AT EnglishLogicKernel DOT com
9 4 9 \ 5 2 5 - 5 7 1 2
-----Original Message-----
From: ontolog-forum-bounces@xxxxxxxxxxxxxxxx
[mailto:ontolog-forum-bounces@xxxxxxxxxxxxxxxx] On Behalf Of John F.
Sowa
Sent: Sunday, October 17, 2010 8:30 PM
To: ontolog-forum@xxxxxxxxxxxxxxxx
Subject: Re: [ontolog-forum] Interpreting OWL
On 10/17/2010 10:59 PM, doug foxvog wrote:
> It seems to me that the graph would have many disconnected
subgraphs,
> and certainly not be a single tree.
Yes. Technically, it would be a forest.
> The unusual case would be when there was a loop. This could
happen if
> a professor were to go for another PhD after a number of years,
and
> have as a thesis advisor in the new field a former student or even
> student of a student.
Yes.
On 10/17/2010 11:20 PM, Rich Cooper wrote:
> Is there any looser constraint, or must the graph be a DAG at all
to be
> fully distinguishable<persons/objects/things> among
the paths?
If all relations are symmetric, the graph would not be directed.
But most relations are not symmetric.
John
_________________________________________________________________
Message Archives: http://ontolog.cim3.net/forum/ontolog-forum/
Config Subscr:
http://ontolog.cim3.net/mailman/listinfo/ontolog-forum/
Unsubscribe: mailto:ontolog-forum-leave@xxxxxxxxxxxxxxxx
Shared Files: http://ontolog.cim3.net/file/
Community Wiki: http://ontolog.cim3.net/wiki/
To join: http://ontolog.cim3.net/cgi-bin/wiki.pl?WikiHomePage#nid1J
To Post: mailto:ontolog-forum@xxxxxxxxxxxxxxxx
_________________________________________________________________
Message Archives: http://ontolog.cim3.net/forum/ontolog-forum/
Config Subscr: http://ontolog.cim3.net/mailman/listinfo/ontolog-forum/
Unsubscribe: mailto:ontolog-forum-leave@xxxxxxxxxxxxxxxx
Shared Files: http://ontolog.cim3.net/file/
Community Wiki: http://ontolog.cim3.net/wiki/
To join: http://ontolog.cim3.net/cgi-bin/wiki.pl?WikiHomePage#nid1J
To Post: mailto:ontolog-forum@xxxxxxxxxxxxxxxx