Dear John, Ed, Matthew,
I'm wondering about the interplay of verb tense in a model that envisions "one temporal part that is pump 123 during February 2013, and another temporal part that is pump 123 for the first 6 weeks of 2013".
Take a Person for example, with subclasses Boy and Man. [MW>] The main problem with this is that Boy and Man are not subtypes of person. For Boy and Man to be subtypes of Person, each Boy is a Person, and each Man is a (different) Person. What would be correct is that Boy and Man a subtypes of StateOfPerson, and that each StateOfPerson is a temporalPart of a Person. Regards Matthew West Information Junction Mobile: +44 750 3385279 Skype: dr.matthew.west matthew.west@xxxxxxxxxxxxxxxxxxxxxxxxx http://www.informationjunction.co.uk/ https://www.matthew-west.org.uk/ This email originates from Information Junction Ltd. Registered in England and Wales No. 6632177. Registered office: 8 Ennismore Close, Letchworth Garden City, Hertfordshire, SG6 2SU. Person:X can be related with Boy:X via say "Person:X was:this Boy:X" where the Boy:X resource has an is:during relation for the boyhood state (plus an optional is:as-of relation to a timestamp for temporal provenance) while Person:X has an is:during relation relating to the person's lifetime. Of course, during a period of time, "Person:X is:this Boy:X" perhaps even with prospective information related via "Person:X will-be:this Man:X". At the same time (no pun!) would be triples "Boy:X is:this Person:X" and "Man:X will-be:this Person:X". Pointedly I see similar resources applicable to personal roles too, such as Voter:X, Citizen:X, Father:X, Employee:X, Expert:X and so on -- to me, these are all equally valid states for a Person, each with a specific data model, the sum of which is more manageable than various gruesome alternatives coming to mind that don't explicitly involve verb tenses.
I think such representation of state is crafted in a manner quite intuitive to most, easy to query/join, and thus likely to be 'reused'. How does this strike you?
thanks/jmc On 2/3/2014 1:50 PM, Barkmeyer, Edward J wrote: More insertions below. I think we were talking past each other, and we agree on the idea that the ‘state’ is the thing of interest and the ‘isTemporalPartOf’ relationship is one characterizing property of all such ‘state’ things. -Ed Dear Ed, Matthew, The problem I have with the 4D model in Part 2 is exactly what you describe: - theWholeLifeIndividual is a partially ordered set of states (temporal parts). This allows different sequences of states to exist in different views. [MW>] They do not have to be sequences. - the temporal parts are distinguished by “spatio-temporal extent”, but we don’t say how spatio-temporal extents are identified! [MW>] I thought the identity of spatio-temporal extents was well understood. It is its spatio-temporal boundary. So for a temporal part, that can be conveniently defined by the whole life individual(s) (there may be more than one) it is a temporal part of, and its start and end date/time. [EJB] I’m not talking about what a spatio-temporal extent of a thing IS; I am talking about how you IDENTIFY one. If I want to identify a temporal part of a pump, I will give you a serial number and a timestamp, or a layout tag and a run number, or any number of other mechanisms. That identifies a ‘temporal part’ that is fuzzy, but sufficiently clear for a given purpose. The problem is that it may be too fuzzy for another purpose, or too strangely identified for some other purpose to have any idea what temporal part it is! Ultimately, the idea for temporal parts is not about having the upper ontology notion, but about having modeling practices, and data capturing practices, that identify the states of the ‘whole life individual’ in a way that is useful for a known set of purposes. Not in most of the Part 4 ‘template’ uses of TemporalPart, and not at all in the RDL(s). For example, if a temporal part of a class [MW>] A class does not have a temporal part (second time I’ve pointed this out). is nominally identified by its extension, the temporal part cannot be effectively identified in practice. [MW>] I have no idea what you are trying to say here. Please give an actual example. - because of these two properties, I can’t tell in general anything much about overlap of temporal parts. [MW>] Of course you can. The spatial extents are determined by what the temporal parts are temporal parts of, and the temporal extent is determined by the start and end time. Anything that overlaps with both, overlaps. So if I have one temporal part that is pump 123 during February 2013, and another temporal part that is pump 123 for the first 6 weeks of 2013, then I can determine that they overlap, and that for the period of overlap, any temporally divisive property of each of these states is true for the intersection of them. [EJB] Ah, we are finally coming to the idea of interest. A modeled element has a reference scheme and ‘individual X at timestamp’ is ONE possible scheme for identifying a state. But if I have one temporal part of the Pump that was used in Run 306 and another that was measured on 14 Jan, how are they related? Could they be the same temporal part? Maybe. Not only do we have to check the date of the run, we may have made the measurement before starting the Run, so the temporal extents are different, but for the purposes of the process log, it is almost certainly the “same” temporal part. I contend that the ‘temporal part’-ness is an aspect of the Pump model that is important to some data elements, and for those data elements the modelers need to know how the distinctions in that aspect are made and labeled. But that same idea will be true for identifying ‘whole life individuals’ and ‘events’, etc. There is nothing special about temporal parts. It is just that the modeler needs to understand how to model things that change, in the way those changes are perceived as creating ‘states of interest’ of the “whole life individual”. That those states are ‘spatio-temporal’ is a philosophical view of things that contributes nothing directly to the practice. Process modeling people have understood timestamps for 50 years without a 4D ontology. Further, they use events and activities and other means besides clocks to identify time intervals, and spatial properties may be subsumed in a label for a thing or a place. The concern is always about having sufficient information to identify a ‘state of interest’ and its interesting relationships to other states in other views. [EJB] In so many words, the 4D ontological ‘temporal part’ doesn’t tell me anything I need to know about how to model states of interest. It gives me one RDF verb that is important in describing ‘state’ things. All the other properties of a ‘state thing’ are dependent on its useful classifications and the viewpoint of the model. Modelers have been able to deal with temporal parts for years by specifying identification/reference schemes that distinguish the states of interest. And yes, when there is no way to correlate two schemes, the overlaps cannot be determined. But Part 2 does not solve that problem. [MW>] I think you are talking about classes of states here, not particular spatio-temporal extent. Part 2 was never intended to solve that problem. This is just more detail that goes in the RDL. Classes of state are classes of individual (subtypes of possible individual) and so there is exactly the right place to put them. With respect to the state of the fluid and the state of the equipment, I disagree -- the states involved are NOT the same thing. Only the high-level abstraction is the same thing. (I’m sure that is what you mean, but it is misleading.) [MW>] Could you explain exactly what you mean by them being different? Of course they can be members of classes of state. I’ve already listed the different ways in which states participate and the ways they might be classified. What else is there that you seem to find missing? [EJB] I meant that there are NO common modeled properties of a state of the fluid and a state of the pump. They both have ‘spatio-temporal extent’ but the reference schemes for labeling the states are different, and the temporal extents are very different. The states of the fluid are measured dynamically (when we care) and those measurements are used directly in controlling the process. The state of the pump may be measured dynamically, but it is usually measured repeatedly during maintenance and inspection operations, or when some ‘performance measure’ of the EFFECT on the process stream tells us there has been an important change of state in the pump. What these states all have in common is that they have (known) spatial coordinates, which are associated with the identifier for a long-term state of the pump or probe, and they have some kind of timestamp which locates a point somewhere within the spatio-temporal ball that represents the state in 4-D. So, the notion that all these states have spatio-temporal extents is common. And the idea that the ‘whole life individuals’ change over time is common. So, yes, at 50,000 feet they are ‘the same thing’. [MW>] Again. Please give specific examples of what you think is missing. [EJB] The fluid state is measured at a point in the stream (identified by the instrument) and at a time. The Pump state is identified by a tag or something that can be construed to a location, and a time of measurement, which may be before the run and is assumed to be more or less constant until the next measurement. OK, they both have a label and a timestamp, but the labels label different things in different relationships to the states and the timestamps have different interpretations with respect to temporal extent. What I am trying to say is that the important thing is to identify these labeling properties and an understanding of the nature of the state they label. That the things are ‘spatio-temporal states’ is even less useful than saying the Pump is an instance of Equipment; at least the latter high-level abstraction has some common modeled properties. But we may only know about changes of state in the pump because we observe (measure) unexpected changes of state in the process fluid, or because we replaced a part. So, what is important is HOW (and whether) spatio-temporal coordinates are used in identifying the states and the MEANINGS of the states themselves. [MW>] It is not so much the state itself, but what you say about it that is important. The state is just a coat hanger to give context. [EJB] YES! The only property that ‘temporal part’ has is ‘isTemporalPartOf’ a unique WholeLifeIndividual. That relationship has axioms (it is a particular part-of relationship), but I don’t think WholeLifeIndividual has any axiomatic properties. This has some value for reasoning. In exchange models it is one RDF verb that relates two ‘things’. If we have to have a template for every real property, then we need one template that generates one triple. After that, the ‘temporal part’ thing and the ‘whole life individual thing’ can participate in other relationships, but they never again need to appear in the same template, for data exchange. [EJB] I think the problem I really have with ‘temporal parts’ arises from the clumsy way in which Part 4 uses them. And that seems to be because Part 4 attempts to define a language for representing conceptual schemas, as opposed to representing plant data. Much of it seems to be about saying that a temporal part of an X can have (always has) property Y. Given OWL, we don’t really need to invent a new conceptual schema language to state constraints like that. So all the templates that fit that purpose can be deleted, and will never be missed. We can and should use OWL to do that, and it defines a useful RDF form. In data exchanges, a temporal part is just a thing that has the isTemporalPartOf relationship to some other thing, and those two things individually have other properties of interest. Somehow this simple model has been buried in a lot of not-invented-here hoopla in 15926. The information that is exchanged depends on these latter factors, which are specialized for different systems of states for different things. The commonalities are only abstractions of the concepts described in the exchanges. So at 500 feet, process fluid states and pump states are very different things. They have different identification mechanisms and different kinds of uncertainties in their “spatio-temporal extent”. [MW>] This is just more generality. Again, please give specific examples. In so many words, the 4D stuff is a way of thinking about certain practical problems, but it is not about WHAT you think about the individual problems. Part 2 is a model made to guide the modelers. [MW>] Indeed. But the model made to guide the modelers is not clearly a useful model for the data exchange itself. [MW>] It’s possible to use it, with an RDL. But I leave it to implementers to decide whether that is the most appropriate model for the exchange they with to do. Templates are an alternative. I think David is right that we are confusing the definition of a modeling language with the use of the language to create models. [MW>] Part 2 has two objectives: 1. To provide a way to say anything that is valid, 2. To reduce to the minimum the different ways you can say something valid. It was definitely not trying to be a comprehensive (or at least sufficient) vocabulary, that is the RDL. What we really want from Part 2 is that the modeler is aware that PumpState is an important concept, and that it has the isTemporalPartOf property with the range restricted to Pump, and that many of the dynamic properties we assign to a Pump are properly assigned to a PumpState. [MW>] You are looking in the wrong place. Part 2 is and never was intended to be the whole solution to the whole problem. But it is in fact quite likely that PumpState is called “pump data sheet”, which has a date, a related Pump (the IsTemporalPartOf relation), and a set of measured properties. We want to enforce the discipline here, but how far that extends into the model structure and the model nomenclature is quite another thing entirely. My observation is simply that using a property like isTemporalPartOf everywhere is only somewhat economical, and the domain and software engineers don’t recognize the term. Without common axioms, the use of the common term for all such relationships has very limited value in integrating models. [MW>] And that extra layer is what templates are for based on Part 2 and the RDL. By the way, I tried to find templates that forced repeated creation of the temporal whole part relationship as you claimed in an earlier post, but could not find any. Please could you give specific examples of where you have found this a problem? BTW, you wrote: “A design is the specification of one or more possible individuals, and as such is a class, so does not have temporal parts.” I also agree that the specification part of a design (element) is a class, but the design (element) itself is a thing, not a class, because it can change. [MW>] I’m not sure what you mean by a “design (element)”. Do you mean the (one or more) thing that will be built? Or do you mean a part (by class) of the design? [EJB] I mean the “Pump” thing that shows up on the P&I diagram with tag P114-A. That thing is a DesignElement – a “structural part” of a Design (Model). (And please don’t confuse the DesignElement with its graphical representation; by now we should be past that.) It is associated with set of requirements that may be taken to represent a “class” of pumps. In a later revision of the P&ID, the requirements for that “pump” might change, and the DesignElement will then be associated with a different “class”, but it will retain its identity as a “functional object” describing some step in the transformation of the process fluid. The “whole life” DesignElement could thus be viewed as having TemporalParts, each of which is a “version” of the DesignElement, but each of these has an associated engineering development, evaluation and approval practice. So versions are a lot more than just “temporal parts”. Unfortunately, I cannot find a concept like DesignElement or “specification version” in the upper ontology, and nothing useful in the RDLs. So, I model a design as a ‘functional object’ that is related to a specification (class). (But there is no Template for that, so there follows some contorted circumlocution. There is no useful model of ‘design element’ in the RDL.) [MW>] I’m surprised if there is not a classification template (which would be the appropriate one) since the functional object will meet the specification of the design. [EJB] This is part of the SC4 confusion. Classification (in this case) is about the relationship of an actual Pump to a characterization of Pumps, that is, about the relationship of a physical Pump to the specifications carried in the DesignElement. And a consequence is that the physical pump in place in the plant may carry the same ‘tag’, the “P114-A”. But the specification exists, and the EPC can fuddle with it, long before there are any actual pumps involved. The Design is a thing, its structural elements are things, and the engineering processes manipulate those things and their ‘temporal parts’ (if you must). The DesignElement is not the characterization it carries (the Pump “class”). If you change a requirement, the resulting characterization is a different “class”, but the DesignElement is the “same” (WholeLifeIndividual). And, as you know, I find the idea that a class can have members that are ‘possible individuals’ to be ontologically annoying and unnecessary [MW>] Why? How else do you propose to deal with project plans and other things you intend to bring about in the future? [EJB] A plan is a thing, an actual individual. And there are other actual things that are “parts” of that plan. There is a difference between a plan and any real event that implements the plan, although both can be described by the same propositions – two different classes characterized by similar properties, or one class in which the individuals have an associated ‘context’. A future situation is an actual thing whose lifetime happens to be a future time interval. In SC4, there are lots of rat-holes to go down; we don’t need to add possibilia. , particularly, since Part 2 treats “class” as intensional (the predicate) rather than extensional (the set of things in the UoD that satisfy the predicate). [MW>] It is a little more nuanced than that. In Part 2 a class is extensional in that it is defined by its membership and its membership does not change over time. However, we allow that you do not necessarily know, care, or record all the members of the class. So it is also quite appropriate to have intentional definitions to identify members when you discover them and they are of interest. I do agree that modelers need some guidance on the formal representation of the concept of ‘ordering a battery’. Perhaps ordering a possible battery is better than ordering from a class of battery. I prefer the idea that one orders from a catalog entry, which is associated with a class of product. Again, this separates the object (catalog entry) from the class. But you still need the idea: (associatedWith catalogEntry Class), which puts the Class in the UoD. But none of this is in Part 2, so we order ‘possible batteries’. [MW>] Of course there is work to do. What you are supposed to work out is that a catalog entry (product model) is a class that you want some number (aggregate) of possible individuals that are members of that class. Again, the detail (battery, order) is in the RDL. What you get in Part 2 is the data model for activity and class of activity which give you the structures you need to drive with the RDL data, and probably develop appropriate templates for. [EJB] I want an aggregate of real individuals that are members of the class, not an aggregate of ‘possible batteries’. A ‘possible battery’ cannot provide power for an ‘actual instrument’. The point of my example is that an order refers to the class, full stop. The verb is ‘party orders catalog-entry’ or ‘party orders class’, not ‘party orders individual’. The meaning of ‘orders’ is somehow associated with a ‘future’. This is a “deceived by the flight” kind of thing: people think (party) orders (product), because they say they ordered “4 batteries”, but the real verb is (party) orders (quantity) of (product class); they actually ordered ‘4 count’ of ‘battery’. And when you see it that way, you don’t need ‘possible batteries’. [EJB] An even uglier verb form in this area is verbs of specification and change. When a contract sets a delivery date for goods, there is no individual time interval that satisfies ‘delivery date for shipment xxx’ for the contract to ‘set’. Rather there is a class ‘delivery date for the shipment of xxx’, whose extension is unknown. When the contract ‘sets’ that date, it simply defines the extension of the class. So, the verb is not (contract) specifies (date), but rather (contract) specifies (date class). And if you change the date, after one is set, you are not in fact changing the time interval that is/was the date (unless perhaps you are Pope Gregory), but rather the extension of the class. [I owe this last insight to one Don Baisley, formerly of Unisys, who described this in a draft standard, and confused most of his audience.] [EJB] As I said to Hans and others in one of the standards alignment projects, ‘PossibleIndividual’ is just another term for ‘class’. Regards Matthew West Information Junction Mobile: +44 750 3385279 Skype: dr.matthew.west matthew.west@xxxxxxxxxxxxxxxxxxxxxxxxx http://www.informationjunction.co.uk/ https://www.matthew-west.org.uk/ This email originates from Information Junction Ltd. Registered in England and Wales No. 6632177. Registered office: 8 Ennismore Close, Letchworth Garden City, Hertfordshire, SG6 2SU. -Ed Dear Ed, OK. We are getting somewhere. [MW2>] Good. Comments labeled below. Dear David, Hi Ed and Matthew, A view from the peanut gallery (i.e. the bowels of projects trying to implement a second, and third 15926-based data integration repository) ... The core of Part 2 is really a modeling language or at best an upper ontology with a particular set of commitments. [MW>] I would say it is both of those. [EJB] Yes, I think at heart Part 2 is some of the semantics for a Knowledge Representation Language, in that it makes a set of fundamental ontological commitments and provides language terms for those concepts. I say ‘some of the semantics’ because the ‘templates’ in Part 4 represent a set of standard verbs that can be used to construct sentences involving domain-defined nouns. So, the rest of the KR language -- the sentence syntax and the semantics of those formation elements – is defined in the templates. That is why people like Ed say it's not an ontology in the everyday sense of the word. Part 2 is more like the W3C OWL standard itself than the W3C Provenance Ontology, for example. So, I see Part 2 is a modeling language that can be the basis for an ontology for process plants held as instances of Part 2. [MW>] Agreed, but a 4D ontology of process plants. [EJB] I think, and I have said, that the 4D-ness is overworked in the template language. The idea that a WholeLifeIndividual can be a sequence [MW2>] It does not have to be a sequence, they can be overlapping. of interesting Temporal Parts is useful, but a given industrial ontology has to identify how interesting states that are the TemporalParts are distinguished, for each class, and how they differ from arbitrary changes of state. [MW2>] They are distinguished by their spatio-temporal extent. It does not matter what class they are. A state may be a member of more than one class of course. In so many words, you have to say what you mean by a ‘state’/TemporalPart and its own persistence. [MW2>] I think I just did. They are really very simple. You can have (in principle) any spatio-temporal extent you like. In practice, the interesting ones are whole-life individuals, and states (temporal parts) of them. You choose which ones are interesting. They may overlap, or not. A state is interesting generally when we want to make a statement about it which is true for all of that state (both spatially and temporally). So if we identify a state of a door that is open, we mean that all of the door (consider a stable door if you like) is open all for the time for that state. The nature of state in the process fluid differs from the nature of state in the equipment lifecycle, which also differs from the nature of ‘state’ in a versioned design specification. [MW2>] I beg to differ. You might want to say different things about a state if it is a fluid, but the state itself is exactly the same thing – a spatio-temporal extent that is a temporal part of some whole-life individual. I have no idea what you mean by a ‘state’ in a versioned design specification. A design is the specification of one or more possible individuals, and as such is a class, so does not have temporal parts. If you have a project that develops a design for a process plant, then you have one (or possibly more) possible process plant with start date in the future that is a member of the class that is the design specification. Classes are universal, so do not change, so do not have states. They do have version and variant relations among them. The Part 2 ontology says individuals, collections, and classes can have TemporalParts, but the nature of ‘temporal part’ (the nature of the ‘states’ of interest) is only defined for collections. [MW2>] Please give me the reference to where this is stated. Only possible individuals have temporal parts. Here is the bit of model where it is defined. Classes of individual can of course have class_of_temporal_whole_part (e.g. projects have lifecycle stages). But as usual, it is important not to confuse levels of abstraction. 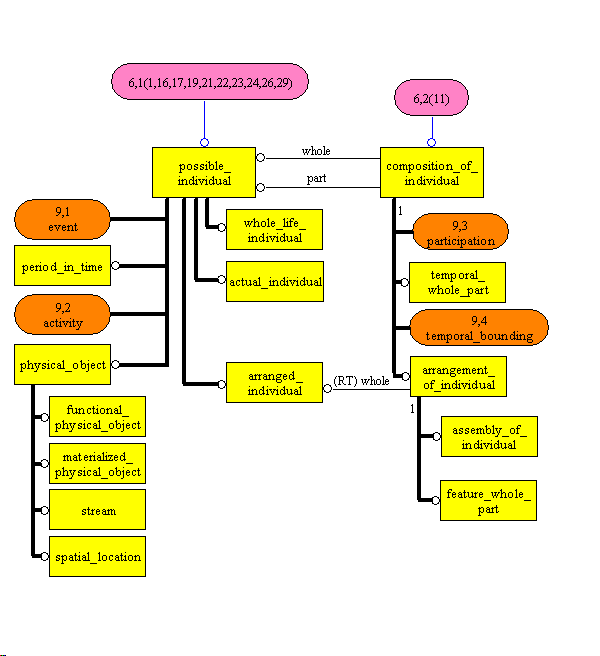
[EJB Experts have created useful industry data repository models for things that have ‘temporal parts’ for over 20 years, by creating their specific state, state identity, and whole life individual notions in their data models/ontologies where appropriate. And Part 2 and Part 4 (the templates) do not alleviate the need to do that! All that is provided is a standard term for the general concept. Part 4 does not provide any real assistance in defining class-specific notions of TemporalPart. [MW2>] I don’t really follow this. Could you give some examples of what you are looking for that you find missing? Even worse, the philosophy of Part 4 seems to be that the modeler must be bludgeoned into using undefined temporal parts in many places, presumably so that the resulting ontology will accidentally work with another ontology that uses a careful temporal parts notion in the same areas. [MW2>] Again, I’m not sure what you mean by undefined. A state is interesting because you want to say something about it. There are relatively few possibilities: 1. You might want to classify it (including status and physical quantities/properties) 2. It might be the state playing a particular role (by which it must be classified) in a relationship. 3. It might be the state participating in a role in an activity, again it must be classified by the role it plays. In the first case, there is no class-specific notion that seems to me to be relevant, you just interested that this state of the whole life individual has this property. In the other cases it is classified by the role played, which should be sufficient to indicate your interest in it. What am I missing here? And that simply does not work: Two viewpoint models for the same space may see different sets of interesting states as the useful temporal parts of the same object. (Another blow to the SC4 theory of accidental integration of ontologies.) [MW2>] Why do you think this does not result in integration? I already said states can overlap temporally, and combining states from different viewpoints means that more states can be calculated that are the intersection or aggregation of the sets of states. Granted you need a mereotopology calculus to do that. In fact I wrote a paper with John Stell a few years ago to make some first steps towards that. (sorry about the URL). https://d2024367-a-62cb3a1a-s-sites.googlegroups.com/site/drmatthewwest/publications/StellWestFOIS2004Final.pdf?attachauth=ANoY7cqusDsg0ObxA--wgthiYKiRR4q_052QOjjhNUcXGWfijh4Fus6k16sFLIoxVQQyU4XMOAjQLsW6m1JsQSE9F8atYvuadOGrge-QApl9N6QQlfsSPpf8m9B4bkB8Pa4WSx1IvKk95s9SIRNzX3NjNnz7JKve96zXksHl3Y6WsJ21rabGN3XF5ZhY5spW80l0KTPQgkDsu0sNPanxLOlQv9AMrY1UJuzj9495WVJXlDY1KuaY532osUXbEoZZJnaQcJz-u-mh&attredirects=0 Further, once I have identified meaningful temporal parts, they are entities in their own right (which is how experts model them in EXPRESS or OWL or UML), [MW2>] Of course they are !!?? and in addition to the properties they have as temporal parts, they also have the property of being a part of some particular WholeLifeIndividual or Class. [MW2>] Of course!!?? But for some reason, most of the templates make me repeat the relationship to the WholeLifeIndividual in stating each characterizing property of the temporal part. [MW2>] I guess this is a question of whether you should help the wise or protect the foolish. On the one hand it does no harm to state this multiple times, and it does if you do it no times – you have a floating state that you will likely never find again – but when you have a lot of properties to state about one state, I can appreciate this could be burdensome. It is possible that object information models could be used to overcome this problem, where an OIM is a set of templates used together. This would then give the opportunity to take the temporal whole part relationship out of each of the other property statements. I would be inclined to go that way. (By the way, there is nothing to stop you defining your own templates that work this way, as long as they a properly grounded and defined in Part 2, you should be fine). It is all part of the mistaken idea that the use of temporal parts must be required even when inadvertent. [MW2>] I’m not sure what you mean by “inadvertent”, but I can appreciate that it can be irritating to be required to say the same thing repeatedly, though in my experience this happens in many practical environments – e.g. spreadsheet or demormalised tables. My evidence for saying that is the fact that when you use Part 2, you do the same tasks as you would in making a normal OWL ontology ... what are my classes, where do they overlap/subsume, what are my relations, what are my properties and their datatypes, etc. So,I actually agree with Ed on this one ... best to treat 15926 Part 2 as a modeling language. Also, because 15926 is dependant on the use of reference *data* and weak on constraint specification, today there is not actually a 15926 ontology at all (in the everyday sense of that word). I think Ed and Matthew are both actually saying that, just in different ways. [MW>] I agree. You can add limited cardinality constraints, and you may be able to put constraints in templates (I’m not sure, but I hope you can) but it is largely constraint free. This goes back to the purpose, which was data integration, and the experience that constraints generally get in the way of that. We were expecting that the constraints would be in the applications that created the data that you were integrating, so there was no special need to focus on constraints in the integration model itself. [EJB] We all agree here. See my response to Andrea. The upshot is that some constraints are definitive, and those must be part of the ontology. Other constraints are imposed by the application. They may be appropriate in a data model, but are not appropriate in the ontology. The problem I have with the KR language created by Part 2 and Part 4 is that, unlike OWL, it does not give me a way to create definitive axioms for a class. [MW2>] I agree. We did look at how we might do this, but it was a bridge too far at the time. I would welcome proposals for how this might be done (not that that counts for anything these days). Just moving to OWL does not seem to be the answer. Regards Matthew West Information Junction Mobile: +44 750 3385279 Skype: dr.matthew.west matthew.west@xxxxxxxxxxxxxxxxxxxxxxxxx http://www.informationjunction.co.uk/ https://www.matthew-west.org.uk/ This email originates from Information Junction Ltd. Registered in England and Wales No. 6632177. Registered office: 8 Ennismore Close, Letchworth Garden City, Hertfordshire, SG6 2SU. Best, -Ed Regards Matthew On 30 Jan 2014, at 10:02, Matthew West wrote: Dear Ed,
Dear Matthew,
What is in Part 2 is not an ontology for process plant information. It is
an ontology for everything, and therefore an ontology for nothing in
particular.
[MW>] That is of course untrue. That is, it is indeed an ontology of
everything, and process plant is something, therefore Part 2 is an ontology
of process plant. It is also a very particular ontology. It is not just
something vague.
We did not set out to create an ontology of everything. We just found that
constraining it to anything less meant that we were forever having to change
our models as new areas were brought into scope. In the end we concluded it
was just cheaper to have a mode of everything, because then we would not
need that continual maintenance.
The RDL should be the reference ontology for process plant information. It
reuses such elements of the Part 2 upper ontology as are useful in
characterizing process plant elements, rather than healthcare elements or
forestry elements, for example. It is the RDL, not Part 2, that will be
used to convey industrial information.
[MW>] Of course, the RDL is where the specifics lie.
There seems to be a view that the RDL is just a 'vocabulary' to be used with
whatever axioms and facts the individual use requires.
[MW>] I think that is a mistake, however, the poor quality of some parts of
the RDL means that this is sometimes the best use that can be made. I am
reminded of Robert Adams description of early version of the RDL as a "list
of famous names". One should not underestimate the utility of even this low
level of use. It does at least address the identity issue - we agree to use
this code/name to indicate we are talking about the same thing.
Even so, if the classifiers and properties are carefully defined (so that
reuse is meaningful), some part of those definitions can be formally
axiomatized.
[MW>] I agree. I'm disappointed more progress has not been made in that
direction.
The important point here is that industry has to agree on what
CentrifugalPump means in terms of structure and possible characterizing
properties.
[MW>] Quite a lot has actually been done on that, although one of the
conclusions is that different companies actually have different requirements
for data about centrifugal pumps, depending on their internal processes. So
at present, there is a long list of properties a centrifugal pump can have
(there are external standards, e.g. API, you can look at for these), and
different selections of these made by different companies.
The fact that it is a "class of inanimate physical object" (part 2) is not
really very interesting.
[MW>] Of course. That is just in case you need an entity type you need to
turn into a table to hold the data.
The RDL is the 'vocabulary' in a KR language whose syntax is defined by
n-ary "templates" in Part 4, and the semantics of that language is defined
in terms of Part 2 concepts
[MW>] Sounds about right.
(i.e., at a high-level of abstraction, which is unfortunate for a language
that has no user-defined verbs).
[MW>] I don't understand what you mean by "A language that has no
user-defined verbs". Especially since you can add both classes of
relationship and classes of activity to the "vocabulary" which are normally
in verb form.
Even worse, a "Centrifugal Pump description" is a "functional object" (Part
2), but it may be viewed as a "subclass of" CentrifugalPump and therefore as
an "instance of" "class of class of inanimate physical object".
[MW>] I really don't know where this comes from. There is no
functional_object entity type in Part 2, there is
functional_physical_object, and class_of_functional_object. Pump is given as
an example of class_of_functional_object.
I would expect "centrifugal pump description" to describe a class of
relationship between some text and the class pump, I have no idea how it
could be considered a subtype of centrifugal pump, because a description of
a pump is not a type of pump.
Please explain further.
This elegant abstraction is so arcane to domain engineers, and to most
domain modelers, that the chance that they will use the Part 2 ideas
correctly is non-existent. Further, it is utterly irrelevant.
[MW>] Indeed. It is unfortunate that the entity relationship paradigm
requires data to be an instance of some entity type, and not just allow you
to declare them as subtypes of entity types, but there it is.
What they need to understand is the difference between a CentrifugalPump
(the physical thing) and a CentrifugalPumpDescription (the model element,
the procurement spec),
[MW>] Ah! That's what it means. An unfortunate name, since
SpecifiedCentrifugalPump would be less ambiguous.
because in the industry itself, the term "centrifugal pump" is used for
BOTH!
[MW>] Of course. Happens all the time, people are good at disambiguation. We
have to tease the different things apart and try to give them names that are
not too offensive, but regular.
And when the RDL introduces a term like Class_of_Centrifugal_Pump when they
mean either of the latter two, it adds to the confusion.
[MW>] Well this is part of the problem of being regular. The problem is that
it is common place to use the term "pump" when we mean both the set of pumps
(things you can kick) and the set of pump models (that are themselves
classes with member from the previous set of pumps). We have to disambiguate
these two usages, and you are really left with two choices, call the pumps
you can kick pump instances (or something similar) and the pump models and
specifications pump, or call the pumps you can kick pumps and the pump
models and specifications class of pump, or something similar, to
disambiguate them. For better or worse, we went for the latter. One reason
being that if we started the name of things that were classes with
class_of... then you knew what sort of thing you were dealing with, and were
less likely to be confused. Of course whichever choice you make, at least
half the people are unhappy (never mind those who thought it should have
been type instead of class). Regularity in naming has a value in larger
ontologies.
API 610 defines "classes of Centrifugal Pump" typically by impeller
structure, but surely the plant design spec has to provide more information
than that, e.g., required flow rate and d ischarge pressure, and what
Emerson's catalogue contains is labeled "Centrifugal Pumps". So the
engineer will be confused if you call the design element or the Emerson
catalogue entry a "class of Centrifugal Pump".
[MW>] I hope there is a "Pump Model" entry in the class library for that
sort of thing. If not I would advocate its addition.
That is, the terminology derived from the elegant upper ontology model gets
in the way of communicating with the industry experts who will develop the
detailed RDL, and with the software toolsmiths it is designed to serve!
[MW>] It shouldn't. It should not even be seen by most. That is one of the
reasons why you should have layers in an ontology.
Two notes from Matthew's comments below:
1. Matthew the experienced systems/knowledge engineer does not see the
commonality between the OMG Model-Driven Architecture, which is about
designing software top-down, and the STEP Architecture, which is about
designing exchange files top-down, because they use different words and have
love affairs with different modeling concepts. My upper ontology for the
problem space of software design sees them as sufficiently analogous to be
instances of a common paradigm.
MW: OK. So you are railing generally against top down development rather
than specifically OMG's model driven architecture of that.
This difference in perception is exactly the problem that the people who
produce software to support petroleum engineering have with ISO 15926 Part 2
and the template-based language for modeling their domain. It ain't their
words, and they don't see their concepts. All of their concepts are in the
RDL.
[MW>] Which is fine, then they should use stuff at the RDL level. I have
never expected software engineers developing CAD systems to suddenly try to
implement their software around data structures based on Part 2. It defines
an integration environment, which may well be virtual, as in the IRING
architecture.
2. Matthew notes that some successful applications of 15926 have in fact
done the application-specific knowledge engineering and then mapped their
concepts and representations back to ISO 15926 Part 2 and Part 4, the
descriptive process that I agree with. Unfortunately, the current approach
in the standards activity is prescriptive as to how this is to be done --
the exchange forms are derived by rote from the templates, converting n-ary
verbs to composites of RDF triples. Any standard KR language already has a
well-defined form for the knowledge captured in that language, but SC4 is
still trying to define one (or more accurately 219 distinct patterns --
their new KR language syntax). So, I see the standardization process
following a different , and undesirable, pattern, from the one used for
successful interchange.
[MW>] I think that is a misinterpretation of what is happening. There is no
prescription about how things will be done. That is just not what standards
are for, and you know it. Standards are permissive unless they are made
prescriptive in national law. The reality is that some people have decided
that it would be useful to agree a way that it can be done using some
particular technologies. The idea for ISO 15926 is to be promiscuous in this
respect rather than prescriptive. So as alternative technologies come along,
I expect groups of people to come together to work out how best to deploy
that technology to integrate and exchange process plant data.
MW: So my conclusion is, Ed, that you are largely tilting at windmills.
Regards
Matthew
-Ed -----Original Message-----
From: ontology-summit-bounces@xxxxxxxxxxxxxxxx [mailto:ontology-
summit-bounces@xxxxxxxxxxxxxxxx] On Behalf Of Matthew West
Sent: Wednesday, January 29, 2014 10:01 AM
To: 'Ontology Summit 2014 discussion'
Subject: Re: [ontology-summit] The tools are not the problem (yet)
Dear Ed,
Well, Matthew, we do seem to agree on the first bullet. What the
15926 community most needs to do is to make a real ontology for
process plant information, translated "improve the Reference Data
Libraries (RDL)". Making useful OWL ontologies is either part of that process -- making
a worthwhile reference ontology -- or it isn't, but it is not
ancillary. The current RDL is a taxonomy, full stop. And instead of
real DataProperties and ObjectProperties, it has 200 "templates" for
constructing those properties from the 'property classes' in the RDL,
which in turn leads to arguments about what the RDF representation of
instance data should look like. With OWL models, the RDF instance
representation is well-defined by an existing and widely implemented
standard. So, choosing ONE suggests itself as the most effective way to
make a Standard! [MW>] Well the RDL is not supposed to be used on its own. The ontology
is in Part 2, and the RDL provides specialized uses of it, and the
templates pick out particular uses of bits of Part 2 and the RDL. Also
the RDL is not simply a taxonomy, though parts of it may be, sometimes
erroneously.
The underlying problem here is the Model-Driven Architecture approach,
as formalized twice in TC184/SC4. First, you make a two-tier
conceptual model of the space, in a language that is supposed to be
suitable for conceptual models, independent of "platform class"
(object-oriented, relational, tree structure, description logic). The
top tier is a collection of meaningless abstractions that is supposed
to be the basis for integrating models (in lieu of looking at the
relationships among the model viewpoints and content). The second
tier is many separate models of useful information in the problem
space, which are forcibly coupled to the worthless top-tier concepts.
Then you "map" the conceptual model to some implementation form, using
a well- defined rigorous process. Of course, the implementation forms
are specific to "platform class", and the conceptual models are not
really independent of platform classes, because they have their own
structuring rules, and the modelers h ave existing prejudices. So, we
end up with rigorous methods for putting a square peg in a round hole. [MW>] I'm not sure I recognise this as what I understand by Model
Driven Architecture (which I take to be a series of models,
meta-models and meta- meta models) or even the STEP architecture,
which your description more closely resembles. However, neither the
meta modelling approach of OMG or the STEP architecture approach
applies to ISO 15926. The approach in ISO
15926 arose from precisely looking at the relationships among model
viewpoints and content, and then looking at how they could be integrated.
There are no meaningless abstractions (i.e. just data structures to
which meaning has to be assigned in context, by e.g. mapping tables).
Though there are certainly some very abstract concepts.
For what it is worth the ISO 15926 conceptual architecture is a single
level in which the models, meta-models and meta-meta models all reside
together (hence recent talk of namespaces). The only other thing is
the language in which it is defined, which for part 2 was EXPRESS.
This was not an ideal language for the purpose - since it essentially
forced the split between data model and data - but it is what we had.
When a more appropriate language emerges that can cope with ISO 15926
as a single level, I hope we will migrate to it. OWL shows some promise,
but still had important limitations.
A consequence of this approach is that the body spends a lot of time
defining modeling conventions, and even more time defining
architectures, methodologies, and mapping formalisms, none of which
has any direct value to industry. And the mismatch between the
conceptual structures and the vogue implementation structures creates
ugly exchange forms for otherwise well-defined information concepts.
[MW>] Yes. That does sound like STEP.
Coming back to the thrust of the Subject line, I have come to the
conclusion that this process is upside down. What you want to do is
create a conceptual model ('ontology') for the problem space in some
formal language, and define the XML or RDF or JSON exchange schema for
THAT model. Then you need a mapping language that explains the
relationship of the chosen exchange form to the conceptual model.
That is, you DESCRIBE what you DID, rather than PRESCRIBING what you
MUST DO. (In engineering, this is the "trace" from the design to the
requirements.) The great advantage of this approach is that it allows
engineering choices that are convenient to the implementer community!
And it can be used to describe other engineering choices made by other
groups defining exchange forms for the same or closely related
concepts. This is a top-down engineering process that allows for tradeoff
in the product design. [MW>] That should work in an ISO 15926 environment, and is what, as
far as I know, many people have done. A typical project might take a
look at the RDL and templates for coverage of their domain for simple
reuse, then come up with its own conceptual model, then map it to the
ISO 15926 data model, templates and RDL. Your structures are in principle,
just more templates. Mapping to Part 2 and the RDL is really part of the analysis, which
will cause questions to be asked about what you really mean, but that
will help the work you have done to be reusable, as well as improve
it. Almost certainly, you will find there are things missing that you
need, (i.e. the mapping will be
incomplete) so you need to add those things (usually to the RDL). The
mapping becomes the formal definition of what you have done. One
result of this, is that any data you create can be mapped through to
the underlying data model for reuse in other schemas where the data
overlaps. That is how integration happens. Developing Part 11 went somewhat like
that.
Way back in the 1980s, the ANSI 3-schema architecture for database
design views the process of design as beginning with viewpoint schemas
for the participating applications. These schemas are then integrated
(not
federated) into a conceptual schema that relates all the concepts in
the viewpoint schemas. The resulting conceptual schema is the
relational model of the stored data (the reference ontology). The
formal viewpoint schemas (external views) are then derived from the
conceptual schema by 'view mappings' that actually transform the
stored data into the organizations demanded by the views (using
"extended relational operators"). The SC4 two-tier modeling mistake
is failing to realize that the process begins with the view schemas
that have direct VALUE to industrial applications, and that the
integrating schema, which allows for new and overlapping applications,
is DERIVED from them. We have confused the organization of the
results with the organization of the enginee ring process, and once again
we have canonized an upside-down approach. [MW>] Obviously I disagree. In ISO 15926 we followed closely the 3
schema approach, to get to the conceptual schema, which we carefully
designed to be extensible. We went through multiple evolutions and
revolutions in developing the conceptual schema over a 10 year period
to achieve something that was reusable, stable and extensible.
My biggest problem with 15926 is the amount of religion attached to
these rigorous top-down approaches, and the enormous resource
expenditures on make-work that that religion engenders.
[MW>] If you are employing a top down process, then you are certainly
doing it wrong - unless you really have a green field, and it's a
while since I've seen one of those.
The quality of the results suffers seriously from this diversion of
effort. And I would bet that the so-called 'pre-standardization achievements'
were accomplished using the inverted engineering process that I
describe, each with its own agreement on exchange form.
[MW>] I expect all benefits are achieved in that way. The cycle is
supposed to be that you raid what you can from the larder, and add
back what you found missing for others to use. Reducing reinvention is one
of the benefits.
Further, what I see appearing in the implementation community is
projects making their own concept models and their own engineering
choices and then tracing back to the RDL, and the required religious
rites, in annexes. [MW>] I don't have a problem with that approach. I would hope that
doing the mapping would add some value to the analysis process, rather
than being a tick box exercise - which is of course a waste of space.
If you have done a good mapping, your data is integrable with other
ISO 15926 data when it is required to repurpose it.
-Ed
P.S. Yes, I agree that this whole discussion is a holdover from last
year's Summit topic. You don't get to do top-down engineering for Big
Data. [MW>] I think the big mistake you are making is assuming that using an
upper ontology necessarily means you are doing top down engineering.
The purpose of an upper ontology (at least in ISO 15926) is so that
you can add more bits that work together to make a greater whole that
can be reused by others. Some discipline is required to make that
virtuous circle work, but it is certainly not top down engineering.
Regards
Matthew West
Information Junction
Mobile: +44 750 3385279
Skype: dr.matthew.west
matthew.west@xxxxxxxxxxxxxxxxxxxxxxxxx
http://www.informationjunction.co.uk/
https://www.matthew-west.org.uk/
This email originates from Information Junction Ltd. Registered in
England and Wales No. 6632177.
Registered office: 8 Ennismore Close, Letchworth Garden City,
Hertfordshire,
SG6 2SU.
--
Edward J. Barkmeyer Email: edbark@xxxxxxxx
National Institute of Standards & Technology Systems Integration Division
100 Bureau Drive, Stop 8263 Work: +1 301-975-3528
Gaithersburg, MD 20899-8263 Mobile: +1 240-672-5800
"The opinions expressed above do not reflect consensus of NIST, and
have not been reviewed by any Government authority."
-----Original Message-----
From: ontology-summit-bounces@xxxxxxxxxxxxxxxx [mailto:ontology-
summit-bounces@xxxxxxxxxxxxxxxx] On Behalf Of Matthew West
Sent: Tuesday, January 28, 2014 3:49 AM
To: 'Ontology Summit 2014 discussion'
Subject: Re: [ontology-summit] The tools are not the problem (yet)
Dear Ed,
That's not what I said, and you know it...
It does not follow from success having been achieved that there are
not further opportunities for investment.
In particular, ISO 15926 was developed using a previous generation
of languages and technology and we should look at how to move it
forward. Not that this stops it being used - it was designed to be as
independent
of
the implementation technology as possible.
My priorities would be:
1. Improve the RDL. There is a lot that is useful there, but also a
lot of
crud
that has crept in - and that is where the pesky details belong.
There are
also
areas where it could usefully be extended. The advantage of work in
this area is that there are no obvious technical barriers (but there
do seem to
be
political ones). There are quick wins here.
2. I would encourage development of OWL versions of ISO 15926, but
in particular, improvements to OWL that would make it better suited
to the expressiveness of ISO 15926, and for data integration as well
as
reasoning.
3. I would encourage the development of the IRING architecture and
implementations of it. In particular I would be looking for Quad
store technology. ISO 15926 is naturally quad based - a triple plus
an
identifier for
the triple.
Whereas much of the costs of moving engineering data through the
plant lifecycle have been removed, there is still plenty of
opportunity to
improve
collaboration through the supply chain, and reduce project
development times (which can be worth $1m/day for larger projects).
Specifically, I would be looking for equipment manufacturers to be
publishing
data sheets as ISO 15926 linked data, as well as IRING
implementations to help with collaboration between owners and
contractors in developing requirements, and reviewing designs.
And no, I don't think there is a need to standardise how a tool can
implement
a conforming exchange for point to point exchanges. I think that is
a
tactical
matter. I'm not even sure you need that for IRING. What you do need
is an understanding of how to map data from various tools to ISO
15926, and out again, but I don't see how it is appropriate to
standardise how that
mapping
is done since that would be specific to each particular tool.
Regards
Matthew West
Information Junction
Mobile: +44 750 3385279
Skype: dr.matthew.west
matthew.west@xxxxxxxxxxxxxxxxxxxxxxxxx
http://www.informationjunction.co.uk/
https://www.matthew-west.org.uk/
This email originates from Information Junction Ltd. Registered in
England and Wales No. 6632177.
Registered office: 8 Ennismore Close, Letchworth Garden City,
Hertfordshire,
SG6 2SU.
-----Original Message-----
From: ontology-summit-bounces@xxxxxxxxxxxxxxxx
[mailto:ontology-summit-bounces@xxxxxxxxxxxxxxxx] On Behalf Of
Barkmeyer, Edward J
Sent: 27 January 2014 19:09
To: Ontology Summit 2014 discussion
Subject: Re: [ontology-summit] The tools are not the problem (yet)
Matthew,
OK. 15926 is highly successful, and there is no need for further
development
of access mechanisms, templates, OWL mappings or any of that stuff,
because the useful stuff is already in wide use in industry. So
NIST and
the
USA need not invest further effort in the standards work on 15926,
except
in
the development of useful 'reference data libraries', i.e.,
'reference ontologies for process plants'. How a plant design tool
can implement a conforming exchange using one of those ontologies is
already standardized and widely implemented, right?
That is, after 10 years, we have standardized everything we need
except
all
those pesky details that are actually used in designing and building
and operating a process plant.
-Ed
-----Original Message-----
From: ontology-summit-bounces@xxxxxxxxxxxxxxxx [mailto:ontology-
summit-bounces@xxxxxxxxxxxxxxxx] On Behalf Of Matthew West
Sent: Sunday, January 26, 2014 1:22 AM
To: 'Ontology Summit 2014 discussion'
Subject: Re: [ontology-summit] The tools are not the problem (yet)
Dear Ed,
You are indeed rather late to the party.
[EJB] I don't think I have seen an industry "success story" about
15926, even for 'peer-to-peer application interfacing'.
MW: You certainly won't find them if you do not look. How about:
https://d2024367-a-62cb3a1a-s-
sites.googlegroups.com/site/drmatthewwest/publ
ications/STEPintoTheRealWorld.PDF?attachauth=ANoY7crKMLjBQ-
ztRwf87sQKcy0Tsxz
9GcjcUquJFQl3U-
r3rlNRPZQq6NCgA0Xr_yq_IXMo_oG144m4jaJXdYuLOD3q5UsI6CD_YXI8Noh
7We_KilyxzWEwDN9iz0EKYkoIqr_WqVQDjSfzsw3eqgVlf4I81kawZoORdXC0W
0dYNWB2n2w0qdF
PI7i_H6gurmjCiOQ7Rm4VDDdx-
Zdw8kcEhEpuJBojpSZOV_Tn8_jGeMnts83DxVZpnhk4vWQyGDA
cSHR8z1ms&attredirects=0
as just one (pre-standardisation) example of delivering benefits.
There are hundreds of other projects that have used ISO 15926 at
different stages of development in different ways delivering
hundreds of millions of dollars of benefits.
But if that has been successful on a useful scale, there is no
need for further work on anything but the scope of the reference
ontology, because the peer-to-peer interfaces now exist. The fact
is that they don't. There are no standards for them to implement.
(Actually, ISO
15926-11 is a pretty good standard. It provides a very accessible
ontology for the concepts in ISO 15288 (systems engineering for
<something>), and a clear mapping from the ontology to an RDF
exchange form for a model population. The a posteriori Part
4/Part
2 stuff is an
Annex in the back, if anyone cares.
That is the kind of compromise that 15926 needs more of. And I
think David Price and gang will do something similar in Part 12.)
MW: Actually, I think the mistake is thinking that it is the
interface standards that are needed. Getting data out of one
system and into another has never been that big a deal in my
experience. Pretty much any system has an import mechanism with a plain text
format, and pretty much any system has a reporting system that can
create a file to
more or less arbitrary layout.
Job done. If there are problems, they are easily sorted out using
tools like access and spreadsheets. It helps that most data
waterfalls through a series of systems in the process industries,
rather than there being tight integration with a lot of back and
forth in real time. Those requirements have not surprisingly found
themselves in
integrated systems.
MW: Indeed the BIG IDEA in ISO 15926 was having a generic data
model that enables you to say all the sorts of things that are
important, and an extensible reference data library that provides
the specifics to the level of detail required, and to which you
can add anything you need for new domains plus templates that
incorporate those
specifics.
MW: The big issue in integration and exchange between systems was
not the exchange format, but the mapping between the different
codes and names different systems used for the same things. The
real achievement of ISO
15926 is indeed the RDL. As far as I know, by now all the major
design packages for the process industries support the use of an
RDL, including tailoring and extensibility. The oil majors at
least that I have had contact with spend time developing their own
RDLs, these being extended subsets of the ISO 15926 RDL, which
they require to be deployed in their asset management systems
across the lifecycle. So for example, I know that Shell has an
appropriate subset of its RDL
embedded in SAP.
MW: The big thing here is that this makes the interfacing much
simpler, because the mapping - that was always the expensive and
unreliable bit, has largely been confined to history. That is also
where the big benefits have come from. Largely unreported, because
you don't notice costs you didn't incur that you did not need to
incur if you
did things right.
MW: And yes, this is what people have been more recently calling
master data management, we were just working out this was what was
needed in the last century.
MW: So what of IRING and other recent developments? There has
certainly always been an ambition for seamless integration in
developing
ISO 15926.
The reality has been that so far the technology has always fallen
short. XML Schema is OK for defining interface formats, but not
integration (not surprising since it is really a document
specification language). OWL has greater promise, but it is
focussed on reasoning and so has restrictions that are at best
inconvenient for data integration, and much of the current
discussion in the ISO
15926 community is how best to work around those limitations.
IRING, facades, and the possible use of triple stores is currently
where the cutting edge is. I think the IRING architecture has
merit in the long
term. I'm not sure we have the technology to implement it yet.
Regards
Matthew West
Information Junction
Mobile: +44 750 3385279
Skype: dr.matthew.west
matthew.west@xxxxxxxxxxxxxxxxxxxxxxxxx
http://www.informationjunction.co.uk/
https://www.matthew-west.org.uk/
This email originates from Information Junction Ltd. Registered in
England and Wales No. 6632177.
Registered office: 8 Ennismore Close, Letchworth Garden City,
Hertfordshire,
SG6 2SU.
-----Original Message-----
From: ontology-summit-bounces@xxxxxxxxxxxxxxxx
[mailto:ontology-summit-bounces@xxxxxxxxxxxxxxxx] On Behalf Of
Barkmeyer, Edward J
Sent: 24 January 2014 22:57
To: Ontology Summit 2014 discussion
Subject: Re: [ontology-summit] The tools are not the problem (yet)
Hans,
Further comments intertwined with yours below.
[HT] I shudder when thinking about how bad your tooth and nail
will be if what is below is apparently seen as mild comments by you.
[EJB] If so, then what is sacred in your view is largely
irrelevant in
mine.
I had rather thought that we had a common goal -- successful
interchange of plant data over the lifecycle.
this is not only about knowledge engineering; this is about
database engineering using triple stores. (If integrating RDBs
with triple stores and SPARQL is your goal, you should look at
the stuff Kingsley Idehen is doing.) [HT] On what would YOU base
any knowledge, other than facts about all aspects of the plant,
gathered
during decades?
Not
from LOD I hope.
[EJB] I would BASE the knowledge on the repositories of the facts
about all aspects of the plant, gathered during decades. Our
disagreement is about how we would FURTHER ENGINEER that
knowledge.
What EPCs already have ...
What does your would-be triple store have to offer them?
[HT] Ignoring your patronizing last sentence this: I have worked
most of my life in such a large firm, I have been in the
trenches, I have designed the first data bases for engineering
and later the integration of data, resulting in such software.
And so did my colleagues
from other large firms.
But we were faced by the fact that everybody was using something
different with different internal formats and geared to their
(different) work procedures. So when we were entering a joint
venture for a multibillion project we were discussing "your
system or
ours?"
in order to be able to communicate and to satisfy the growing
requirements from the side of the plant owners that they wanted
all information in an integrated fashion. That was why PIEBASE
(UK), USPI
(Netherlands) and PoscCaesar (Norway) we formed, and later
together in EPISTLE (Matthew West et al). So yes, we had our
systems, but these were,
in a globalizing world, silos.
[EJB] Yes, and that was 10 years ago. What came of that? What
"integrated fashion" did they all agree on and implement?
And yes, until now
ISO 15926 is used for peer-to-peer application interfacing,
succesfully as I heard.
[EJB] I don't think I have seen an industry "success story" about
15926, even for 'peer-to-peer application interfacing'. But if
that has been successful on a useful scale, there is no need for
further work on anything but the scope of the reference ontology,
because the peer-to-peer interfaces now exist. The fact is that they
don't. There
are no standards for them to implement.
(Actually, ISO 15926-11 is a pretty good standard. It provides a
very accessible ontology for the concepts in ISO 15288 (systems
engineering for <something>), and a clear mapping from the
ontology to an RDF exchange form for a model population. The a
posteriori Part 4/Part 2 stuff is an Annex in the back, if anyone
cares. That is the kind of compromise that 15926 needs more of.
And I think David Price and gang will do something similar in Part
12.)
And as I started this thread: Standardization is finding a
balance between large ego's, commercial politics, short-term
thinking, hard-to-make paradigm shifts, and for the most lack of
funding. And I might add: the unwillingness to really understand each
other because that
takes time.
[EJB] Not to mention the unwillingness to compromise. "Standards
is politics."
What standards-making should NOT be is academic research. Except
possibly in W3C, successful standards standardize something very
close to what is currently in wide use, so that implementation is
a marginal cost, and the return is wider market and lower cost of
sale. Engineers who create new technologies seek patents, not standards.
The lack of wide success with
TC184/SC4 standards can largely be attributed to the creation of
an unnecessarily high cost of implementation, which results from
the adoption of complex mappings from concept to exchange form.
The concern is: can we develop an integrating ontology that can
be used for semantic mediation between the existing schemas, and
provide a useful exchange form based on the integrating ontology?
... [HT] WE DON'T HAVE an "integrating ontology", other than the
Part
2 data model and the templates derived from that, where the
latters are completely data-driven and representing the smallest
possible chunk of information.
[EJB] Umm... Capturing the concepts needed for particular
information sets ("data driven") is in fact how ontologies are
built. It helps if there are also "common lower ontologies" --
quantities, time, location, identifiers, etc. -- that can be
reused directly. The templates and Part 2 lend very little to the
construction of ontologies for exchanging plant data. Those who
see a value in it are welcome to pursue that value, but they
should not
impose it on others.
As in Part 11, the template mappings can be added as an annex
behind the problem domain ontologies and the specification of
their exchange
form.
What is different is that ISO 15926 calls for explicit
information, where most data bases (and documents) carry
implicit information, making shortcuts, that is understandable
for the initiated only, but not for computers. Examples
galore: an attribute of a process boiler: "fluid category", an
attribute of a pressure vessel: "test fluid" and "test
pressure", an attribute of a centrifugal
pump: "impeller diameter", etc, etc. We are working on "patterns"
that will bridge the gap between implicit and explicit
information
representation.
[EJB] Yes, what is different is that you are making an ontology,
not a data model. But the effect is that you are trying to educate
ignorant software engineers and plant engineers in the art of
knowledge engineering. That is not your job, and it is the SC4
mistake. The requirement for the glorious standards effort is to
have participating experts with the ability to construct good
formal models in the standard. Failing that, it is not your job
to try to produce that expertise by teaching the otherwise
experienced domain engineers your trade. It is necessary to
entice more people with your expertise, or
scale down the project to what you have resources to do well.
You, and those of you who have the background, should be
developing the ontologies from these 'available knowledge'
systems, leveraging the available domain expertise, instead of
trying to create a strict structure in which the neophytes will be
forced to get it right. They
won't: fools are too ingenious. And in the process, you have
created an impediment to participation by expert
modelers. By comparison, you and/or the participating expert
knowledge
engineers, would make a good model, and sort out the missing
objects and the mis-assigned properties, and you won't need all
the overhead to get that right.
[EJB] When an industry group makes an OWL domain model for a small
part of the problem space, the last thing they need is a
requirement to figure how to use the Part 4 templates to express
that model as a derivative of the Part 2 upper ontology. It is a
waste of their time, and
it is irrelevant to their goal.
That exercise is pure cost, with no clear return. There is value
to having someone knowledgeable about the related ontology quality
issues read, and recommend improvements to, their model. If you
see some clear return on the investment of developing a template
mapping to Part 2, then you have a motive for doing that, while they
don't. And ultimately, their data exchange will be mapped to their model,
because that is the model the domain experts understood. If you
transmogrify that OWL model into a bunch of template instances,
you create an added costly learning curve for their implementers
that has no RoI for them or their sponsors. The people who see
RoI in the gi ant triple store can develop the technology to
transmogrify the domain ontologies and data for the triple store
purposes, not force the domain modelers and the domain
implementers to be concerned with it. (In lieu of tooth and nail,
I perceive this to be a compromise
position.)
[EJB] By way of defense of my position, I would point out that
after a mere
15 years of working with the god-awful STEP architecture, the
implementers of ISO 10303 concluded that it provided nearly no
assistance in integrating the conforming models of product data
and processes that were made from diverse viewpoints. That model
architecture added significant cost to the creation of the
exchange standards themselves and even greater cost to the
implementations that had to read the transmogrified data and
convert it back to product information. The theory that uniform
structures will produce concept integration was proven false in
ISO 10303, and the similar theory will
prove false for ISO 15926, even though you are using RDF instead of
EXPRESS.
In making and integrating ontologies, no set of strictures is a
substitute for the application of knowledge engineering expertise.
But their critical path also involves a viable exchange form;
and a clumsy form, born of obsession with triples and upper
ontologies, will interfere with wide adoption.
[HT] Wait and see.
[EJB] Quo usque tandem? There is no profit in saying 15 years later
"I told you so".
-Ed
P.S. I chose to burden the Forum with this email only because I
worry that other well-meaning standards bodies might follow
TC184/SC4's model for the use of ontologies in standards, to their
own
detriment.
(And yeah, that was last year's issue.)
--
Edward J. Barkmeyer Email: edbark@xxxxxxxx
National Institute of Standards & Technology Systems Integration
Division
100 Bureau Drive, Stop 8263 Work: +1 301-975-3528
Gaithersburg, MD 20899-8263 Mobile: +1 240-672-5800
"The opinions expressed above do not reflect consensus of NIST,
and have not been reviewed by any Government authority."
__________________________________________________________
_______
Msg Archives: http://ontolog.cim3.net/forum/ontology-summit/
Subscribe/Config:
http://ontolog.cim3.net/mailman/listinfo/ontology-
summit/
Unsubscribe: mailto:ontology-summit-leave@xxxxxxxxxxxxxxxx
Community Files:
http://ontolog.cim3.net/file/work/OntologySummit2014/
Community Wiki: http://ontolog.cim3.net/cgi-
bin/wiki.pl?OntologySummit2014
Community Portal: http://ontolog.cim3.net/wiki/
__________________________________________________________
_______
Msg Archives: http://ontolog.cim3.net/forum/ontology-summit/
Subscribe/Config:
http://ontolog.cim3.net/mailman/listinfo/ontology-
summit/
Unsubscribe: mailto:ontology-summit-leave@xxxxxxxxxxxxxxxx
Community Files:
http://ontolog.cim3.net/file/work/OntologySummit2014/
Community Wiki: http://ontolog.cim3.net/cgi-
bin/wiki.pl?OntologySummit2014
Community Portal: http://ontolog.cim3.net/wiki/
__________________________________________________________
_______
Msg Archives: http://ontolog.cim3.net/forum/ontology-summit/
Subscribe/Config: http://ontolog.cim3.net/mailman/listinfo/ontology-
summit/
Unsubscribe: mailto:ontology-summit-leave@xxxxxxxxxxxxxxxx
Community Files:
http://ontolog.cim3.net/file/work/OntologySummit2014/
Community Wiki: http://ontolog.cim3.net/cgi-
bin/wiki.pl?OntologySummit2014
Community Portal: http://ontolog.cim3.net/wiki/
__________________________________________________________
_______
Msg Archives: http://ontolog.cim3.net/forum/ontology-summit/
Subscribe/Config: http://ontolog.cim3.net/mailman/listinfo/ontology-
summit/
Unsubscribe: mailto:ontology-summit-leave@xxxxxxxxxxxxxxxx
Community Files:
http://ontolog.cim3.net/file/work/OntologySummit2014/
Community Wiki: http://ontolog.cim3.net/cgi-
bin/wiki.pl?OntologySummit2014
Community Portal: http://ontolog.cim3.net/wiki/
__________________________________________________________
_______
Msg Archives: http://ontolog.cim3.net/forum/ontology-summit/
Subscribe/Config: http://ontolog.cim3.net/mailman/listinfo/ontology-
summit/
Unsubscribe: mailto:ontology-summit-leave@xxxxxxxxxxxxxxxx
Community Files: http://ontolog.cim3.net/file/work/OntologySummit2014/
Community Wiki: http://ontolog.cim3.net/cgi-
bin/wiki.pl?OntologySummit2014
Community Portal: http://ontolog.cim3.net/wiki/
__________________________________________________________
_______
Msg Archives: http://ontolog.cim3.net/forum/ontology-summit/
Subscribe/Config: http://ontolog.cim3.net/mailman/listinfo/ontology-
summit/
Unsubscribe: mailto:ontology-summit-leave@xxxxxxxxxxxxxxxx
Community Files: http://ontolog.cim3.net/file/work/OntologySummit2014/
Community Wiki: http://ontolog.cim3.net/cgi-
bin/wiki.pl?OntologySummit2014
Community Portal: http://ontolog.cim3.net/wiki/
_________________________________________________________________
Msg Archives: http://ontolog.cim3.net/forum/ontology-summit/
Subscribe/Config: http://ontolog.cim3.net/mailman/listinfo/ontology-summit/
Unsubscribe: mailto:ontology-summit-leave@xxxxxxxxxxxxxxxx
Community Files: http://ontolog.cim3.net/file/work/OntologySummit2014/
Community Wiki: http://ontolog.cim3.net/cgi-bin/wiki.pl?OntologySummit2014
Community Portal: http://ontolog.cim3.net/wiki/
_________________________________________________________________
Msg Archives: http://ontolog.cim3.net/forum/ontology-summit/
Subscribe/Config: http://ontolog.cim3.net/mailman/listinfo/ontology-summit/
Unsubscribe: mailto:ontology-summit-leave@xxxxxxxxxxxxxxxx
Community Files: http://ontolog.cim3.net/file/work/OntologySummit2014/
Community Wiki: http://ontolog.cim3.net/cgi-bin/wiki.pl?OntologySummit2014
Community Portal: http://ontolog.cim3.net/wiki/
_________________________________________________________________ Msg Archives: http://ontolog.cim3.net/forum/ontology-summit/ Subscribe/Config: http://ontolog.cim3.net/mailman/listinfo/ontology-summit/ Unsubscribe: mailto:ontology-summit-leave@xxxxxxxxxxxxxxxx Community Files: http://ontolog.cim3.net/file/work/OntologySummit2014/ Community Wiki: http://ontolog.cim3.net/cgi-bin/wiki.pl?OntologySummit2014 Community Portal: http://ontolog.cim3.net/wiki/
|
_________________________________________________________________
Msg Archives: http://ontolog.cim3.net/forum/ontology-summit/
Subscribe/Config: http://ontolog.cim3.net/mailman/listinfo/ontology-summit/
Unsubscribe: mailto:ontology-summit-leave@xxxxxxxxxxxxxxxx
Community Files: http://ontolog.cim3.net/file/work/OntologySummit2014/
Community Wiki: http://ontolog.cim3.net/cgi-bin/wiki.pl?OntologySummit2014
Community Portal: http://ontolog.cim3.net/wiki/ (01)
|