Paul,
I made some notes [CBC] , below.
From: Paul Brown [mailto:pbrown@xxxxxxxxx]
Sent: Friday, October 28, 2011 2:11 PM
To: Paul Brown; Jim Amsden; Cory Casanave
Cc: edbark@xxxxxxxx; [ontolog-forum] ; simf-rfp@xxxxxxx; Sjir Nijssen (sjir.nijssen@xxxxxxxxxxxx)
Subject: RE: [ontolog-forum] Solving the information federation problem
Sorry, there is a mistake in one of the paragraphs – it should read:
Same group of concepts, different organization
This is the most common transformation challenge, and it has nothing to do with semantics. It arises when inherently networked information is represented in tree structures and different parties have chosen to use different information tree structures. If you understand the mapping of the individual concepts (including their relationships) and you have the common abstract concepts, you can mechanically do the transformation with an XSLT or equivalent.
I’d like to offer a slightly different perspective on the discussion. I know I’m jumping into the middle of a conversation, so forgive me if I am re-plowing old ground.
First, I think we have to be clear that we are always talking about encoded representations of the real world. It doesn’t matter what kind of semantic model we come up with, it will never be more than an approximation to reality. Russell and Whitehead figured this out more than a century ago when they tried to model mathematics with logic – and failed. This tells us immediately that we can never have one definitive semantic representation: different perspectives will lead to different semantic models. Think wave theory vs. particle theory in physics. Furthermore, because of these differences, I think it is a given that there will be pairs of semantic models between which we will never be able to define mappings. Again, think wave vs. particle theory.
[CBC] Absolutely agree and a reality we must design for.
So where does that leave us? In a practical sense, people build models of the real world, and these are what they want to share.
[CBC] Yes and no, what we mostly have models of is data structures, not even people perception of the world. We know there are different data structures about the same thing. IMHO I think we need to differentiate semantic/ontological representations of the world and data about those things. This shows up a lot in cardinalities – everyone may have exactly one weight but I may or may know need to know it for a particular purpose and in some cases I may need to know several measurements of weight. The single ontological concept has different representations based on purpose in a context.
These days, most models comprise a concrete model of concepts and relationships (i.e. a schema) that defines the structure of a representation and, for each primitive type, a definition of how that particular real world aspect is encoded. The practical problem people are facing is how to map between representations defined by these models. Here I think it is instructive to take a look at the mapping problems that occur in business applications. In my experience, these fall into the following categories:
· Same concept, different encodings
· Same concept, different terms
· Same group of concepts, different organization
· Merged/consolidated concepts
· Different concepts
[CBC] I would add – different purposes for the same or related concepts. In a model of a record about a person a message to create that record may have a different structure than a message to query that same record.
Same concept, different encodings
This is, in many respects, the hardest one to address at the semantic level, for different encodings generally represent different – and not necessarily compatible – approximations of the real world. This lends itself readily to providing mappings as a service: provide the source value, get the target value. Medical ICD9 to ICD10 diagnosis mappings fall into this category. In some cases (this one in particular) you need additional information to do the mapping, but at the end of the day, it’s a lookup.
A practical note here is warranted regarding the internal architecture of this service. For performance reasons, the most common design pattern for this type of service is to segregate the problem into two parts by creating a lookup table. Optimizing the use of a lookup table is a well-understood problem, so making it perform is not an issue. This also takes the performance pressure off the logic needed to populate the table, allowing sophisticated (but not necessarily efficient) approaches to be used for this purpose. This is an area in which I think the sophisticated semantic modeling of the academic variety (RDF, Owl) might be very applicable.
[CBC] If it is exactly the same concept and we can draw an equivalence, it really becomes an engineering problem and solvable. It is similar but different concepts or those just abstracted differently that are most troublesome. Isn’t this the same as multiple names?
Same concept, different terms
This is a common one, and easily handled with a simple mapping between terms. The semantic version is that both terms are related to the same abstract concept. If you make the assumption that terms appear in multiple schemas (XSDs for messages used in communications), there is significant benefit in modeling the abstract concept and the relationship of the terms. This then makes possible Cory’s notion of a pivoting through the semantic model to get from one term to another. As a side note, this multiple-terminology-for-the-same-concept situation is well represented in the SBVR specification.
Where concepts are primitive types that have encodings, you want an additional mapping between each concept and its corresponding encoding. Relating the concepts tells you what encoding mapping you need. Again, this is well represented in SBVR.
[CBC] But very useful if there is a well-defined way to express the multiple names!
Same group of concepts, different organization
This is the most common transformation challenge, and it has nothing to do with semantics. It arises when inherently networked information is represented in tree structures and different parties have chosen to use different information. If you understand the mapping of the individual concepts (including their relationships) and you have the common abstract concepts, you can mechanically do the transformation with an XSLT or equivalent.
[CBC] Different organizations can mean different world-views and can sometimes be trouble, so this one can be hard. It is also complicated in that in some information-organizations there is information missing that is needed by other representations.
Merged/consolidated concepts
This is actually a variation on the encoding problem in which the encodings for multiple concepts (usually Boolean status flags) have been combined in a single field in one representation and are separate fields in another. This requires a schema for the encoding (so now you have a sub-schema whose nature is different than the parent schema), but once you have that you’re back to simple mappings of the same concept.
[CBC] But very useful if there is a well-defined way to express the consolidation!
Different concepts
This is the hardest problem of all, but it is one that does not require a solution! This is because if two parties cannot agree on what they are talking about, they have no basis for communications – at least at any level that will be encoded in messages going to and from systems. So, from a requirements perspective, I propose that this one be declared out of scope.
[CBC] Agree – but some way to record the determination of “not the same “ may be useful.
What I think we need
I’m sort of thinking out loud here, but I think what would be practical is sketched in the following diagram. Today in many UML tools there are model transformation wizards (MagicDraw has one) that allow you to declaratively specify the relationship between two models (e.g. schemas). Instead of doing this (which has the many-to-many complexity), I’d like to draw on Cory’s concept and instead map each schema into an abstract schema and then be able to generate the requisite schema-to-schema mapping. Note that we’re begging off the encoding-to-encoding problem in that all this transform would be able to do is reference a service that is capable of doing the requisite encoding mapping. The final link is to use this model transformation to generate an implementation-technology specific specification for the actual representation-to-representation mapping (e.g. an XSLT). The reason for this is that this transformation has to perform well, and a run-time traversal of the representation->schema->transformation->schema->representation route will simply not scale in practice. By generating this mapping, you allow vendors to optimize their implementations (in any way they see fit) and decouple the whole semantic structure from the actual run-time execution. The final link, of course, is that someone has to craft and supply the service that implements the encoding map. Note that the architecture I suggested for these maps has the same type of structure: generate a lookup table that can then be incorporated into the run-time environment.
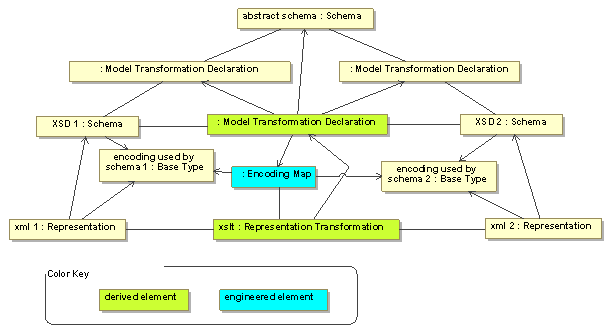
To be honest, I haven’t yet thought through all the implications here, but my gut instinct tells me that this approach is something that industry will adopt and use.
[CBC] I think I mostly agree but that some of this is behind-the-curtain implementation choice. Once we express the concepts and their relationships there can be many ways to leverage that for various implementation styles. (Ok, my MDA Bias is showing through). You also only have to project the “interface points” between the data representations and create a façade from one to the other, this is part of what I mean be “federation” instead of “translation” and simplifies the problem somewhat.
n PCB
******************************************************************************************
Paul C. Brown
Principal Software Architect
TIBCO Software Inc.
Email: pbrown@xxxxxxxxx Mobile: 518-424-5360
Yahoo:pbrown12_12303 AIM: pcbarch
"Total architecture is not a choice - it is a concession to reality."
Visit www.total-architecture.com
Architecture Books:
-- Succeeding With SOA: Realizing Business Value Through Total Architecture
-- Implementing SOA: Total Architecture In Practice
-- TIBCO Architecture Fundamentals
The SOA Manifesto: soa-manifesto.org
******************************************************************************************
From: Jim Amsden [mailto:jamsden@xxxxxxxxxx]
Sent: Thursday, October 27, 2011 10:26 PM
To: Cory Casanave
Cc: edbark@xxxxxxxx; [ontolog-forum] ; simf-rfp@xxxxxxx; Sjir Nijssen (sjir.nijssen@xxxxxxxxxxxx)
Subject: RE: [ontolog-forum] Solving the information federation problem
I too think a lot of the basic parts are already available, but not that well practiced. We're finally starting to get across that tool integration isn't about the structure and interchange of data, its about shared information and what it means. W3C has done a pretty good job dealing with the shared information part. But what's required to make it work is ways of communicating that information to stakeholders so they can reason about it and make decisions about what actions to take to deliver value. I had hoped we could see collaboration between OMG and W3C to move our current investments in modeling languages and ontologies to begin focusing more on delivering that value, and less on the 1% details that make both less approachable to broad communities. Where should it be done? Perhaps nether OMG or W3C. We don't necessarily need more standards right now. Rather we need to explore practical usage patterns and integrations of the standards and tools we already have. This needs to happen in the marketplace, driving evolution and emerging standards by what works.
OWL2, UML2, SMIF, and many others are all headed in the right direction. How can we put them together to leverage their combined strengths and address their weaknesses?
Jim Amsden, Senior Technical Staff Member
Unleash the Labs Solution Architect for Rational EA and ADC Tools
Make a new ULL Request
919-461-3689

Ed,
Well, perhaps you have been a " a thorn in Cory's side ", but I actually don't mind - it keeps us all on our toes.
I think the reason Ed & I have come to different conclusions is that I think semantic integration is happening, Ed thinks it is research. It happens in UML (I know, we do it), it happens in RDF with OWL or Rules (Such as TQ or Revelytix or Sandpiper) and we have used some of these methods as well. It happens in forms of structured English as we see from Sjir Nijssen and Adrian Walker. It happens using FOL+ as we see from Vivomind. I suspect that many of this list have accomplished semantic integration. What has struck me in all of our efforts and those I have observed is that we seem to be hobbling together tools and technologies not designed for this purpose with compromises or shortcomings derived from problems we are not trying to solve. It becomes the art of the practice because of the complexity of doing so.
With the intellectual and developmental resources we have I think we can do better, that is all I am asking for. Lets focus on this problem and do better. I think we have the population & diversity of tools and practice that justify convergence on standards as well as white papers and books. I hope we can spool up some efforts in the ontology community as well as get the next "cleaned up" version of the SIMF RFP out next OMG meeting, and OMG does seem like the place for mainstream modeling standards. And, to make this work, we need mainstream modeling standards and tools designed for purpose. Papers alone just will not make an impact.
Does it need a new language? Don't know for sure - I suspect we do. It at least needs a major "profile" of an existing one. At least a new notation - one building on what we have, may be justified. However, I don't think we need or want a new logic. Others may have other opinions. To be specific about Ed's categories, I think we need standards for how the reference models are represented as well as how they are linked - in my mind these are very connected and should be done together.
Why didn't Cyc do it? It was not their focus. Why didn't W3C do it? I think they got sidetracked by other use-cases as well. Why has it been sticky in OMG? because it says that whatever we have isn't good enough for this problem and some stakeholders would like to send another message. Some of the academic efforts actually seem to be trying overly hard - setting the bar so high it looks intractable. A partial solution is both tractable and valuable. I just don't see any coordinated effort to solve this problem focused on achievable results.
What I would find very interesting from the Ontolog forum is to see if there is some consensus on what works, what is being used and what we should do next to get on with it. What I hope we don't do is get into religious wars and pointless debates.
-Cory
-----Original Message-----
From: ontolog-forum-bounces@xxxxxxxxxxxxxxxx [mailto:ontolog-forum-bounces@xxxxxxxxxxxxxxxx] On Behalf Of Ed Barkmeyer
Sent: Thursday, October 27, 2011 8:11 PM
To: [ontolog-forum]; simf-rfp@xxxxxxx
Subject: Re: [ontolog-forum] Solving the information federation problem
David Price wrote:
> There are of course things that organizations can do to start
> improving the situation, but they have little to do with
> Ontolog-typical concerns and so I doubt that the Ontolog Forum is the
> place to 'get on with' this problem.
>
> I think it's pretty clear now that the OMG cannot do it either - as
> has been proven by the lack of progress on SIMF despite a valiant
> effort on your part. FWIW it's very hard to push through the OMG
> 'everything is a meta-model' and 'vested interests' barriers. Luckily,
> it seems to me that a new language is actually pretty far down the
> list of important mechanisms/approaches wrt information federation anyway.
>
Well, I can agree to some extent. The problem that OMG has in this regard is that Cory is pushing for a *standard* that supports 'semantic integration tools', and he can't name one. I pointed out then that, in spite of 2 EU FP6 projects and millions of euros invested in this, the result was only weak academic tooling, and the three collections of tools I saw chose different organizations and different integrating mechanisms. The OMG Telecomm group put out an RFI for the current state of the art in semantic integration tools and got only one response, from Cory's AESIG. NIST itself is now on its 4th project in trying to define a feasible toolset for some known mediation problems. Part of the difficulty is in agreeing on what the modules should be and do, and part of the difficulty is agreeing on an adequate form for the integrating model.
But the main problem is simply that it is easier to build a one-off mapping of your business data from representation1 to representation2 using XSLT or Java, than to learn to use, and use, the tools to create the ontology for your business data and the tools to map the XML schemas to the ontology and the tools to perform the runtime transformations.
You have to see a broader, longer-term value to the reference ontology to realize any value at all from the extra work.
And the reference ontology has to be able to capture the rules of usage that you will write into your XSLT script. OWL can't. RDF can, if the tool provider invents enough special vocabulary, but what modeling tool will you use to create the RDF ontology? UML with stereotypes and OCLv2 can, but it isn't any easier to write OCL than Java. So there is a serious practical barrier to getting /useable/ and /cost-effective/ semantic mediation tooling. And that is why there are not lots of commercial tools.
Yes, there is enormous value to be realized, IF you can figure out how to create it. We at NIST justify our work in this area as 'research', because we have not yet seen a tool set that is even effective, without getting into useable or cost-effective. And OMG has been given to understand that the IBM evaluation of the situation is similar. So I applaud Cory's idea that this could be an interesting topic for the Ontology Summit, if nothing more than to get a clearer handle on the state of the art in semantic mediation in 2012. The state of the practice is nearly non-existent, which is why a standards project is of doubtful value.
> Cory, this problem belongs in the W3C. I suggested that to you
> previously, and the events of the past year have made that fact even
> more clear in my mind - the solution has to be based in Web and
> Internet standards and technologies.
That is certainly true, but all of OMG, W3C, OASIS and other bodies are working on solutions to various problems based on XML and XML Schema and WSDL/SOAP, and all their dialects and add-ons, which is the meaning of 'Web and Internet standards'. Then we come to who is actually working on solutions using OWL and RDF, and suddenly we have much smaller and more scattered contingent, but there are active committees in all of those, and all in various states of disorganization.
I don't see that W3C is a better choice. The W3C RIF project, for example, had the problem of having to work with OWL and having to work with SPARQL, because those were the W3C invested technologies, even though none of the non-academic rules engines, and at most half the academic ones, had anything to do with either one. (David's employer falls into non-academic category; TopQuadrant support for OWL was an
afterthought.) In short, going to W3C just begets a different set of politics and prejudices.
The problem is not what technologies to use, or where to do the standards work. The problem is to have a community that has semantic mediation tooling and is interested in getting a standard to enable some tools to work together. All of the tool sets I have seen perform the entire mediation function. They need to be able to read XML schemas, and ASN.1 schemas (in HL7), and EDI schemas (in many business applications), and EXPRESS schemas (in manufacturing and construction), and read and write the corresponding standard message forms. They need to have an internal representation for the integrating model (aka reference ontology), and they probably rely on some off-the-shelf modeling tools to provide the input from which that model is created.
It may be advantageous to convert UML to OWL or vice versa, and they probably need to add UML stereotypes or something the like to mark up the incoming model to meet their internal needs for the content of the reference ontology. In addition, they need a runtime capability that is based on a central engine with interface and schema plugins on the input side and the output side, and the semantic maps and reference ontology as inputs.
Now given that you are building a semantic mediation tool suite, you have a list of tool components (which the last draft of the SIMF RFP was still not clear on): reference ontology creation tool, semantic mapping creation tool, general runtime conversion engine, semantic mapping tool plugins for XML schema, EDI, ASN.1, EXPRESS (according to your target market), runtime plugins for the schemas and the corresponding data encodings for input and output, and runtime plugins for WSDL/SOAP and ebMS, and probably other protocols (again depending on target market).
If you build all the tool components as part of your suite, the only standards you need are the existing standards for the schemas and the data forms.
There are already standards for all schemas and encodings, and there are probably open source libraries for reading both and writing encodings.
Unless you want to standardize the Java APIs for that, there is no opportunity for standards there.
Similarly, you probably want the reference ontology creation tool to be some off-the-shelf product of a vendor that does that kind of thing well, and spits out some standard form, like UML XMI or OWL/RDF or RDF or CLIF (if John Sowa has convinced anyone). Alternatively, you could probably use one of these do-it-yourself graphical DSL tools to make your own tool, and then use your own internal reference ontology format as the direct output of your tool. In either case, however, you don't need a standard, unless you need a new language.
Finally, you will need a tool that can take an exchange schema in its left hand, and a reference ontology in its right hand, and enable the domain expert to define the links between the model elements, path to path. This is the critical Semantic Mediation Rules Tool. And you need to define two sets of links -- one is an interpretation rule: data to concept; the other is an encoding rule: concept to data. They are not always symmetric, because the starting points are usually different.
The Semantic Mediation Rules Tool needs to record and export the mapping rules it generates, because those rulesets are the critical input to the runtime engine -- the Mediator. If you expect that one organization will build a Semantic Mediation Rules Tool that can be used by someone else's Mediator, you need a standard for the representation of semantic mediation rules. If not, then not. Does any commercial or academic project not envisage building both the Rules Tool and the Mediator as part of its toolkit? None that I know of. Why would you? Is there any reason to create a standard for communication between my Rules Tool and my Mediator? Not only is it my design choice, it is my IP, and I can improve my capabilities by improving the capabilities of that interface whenever I discover a new and exciting feature that I can add. And I might find it useful to patent my design. The last thing I want is a standard.
In summary, there is the issue of defining a standard architecture, but we would have to do that before trying to standardize any of the interfaces. It strikes me that a useful output of the OMG AESIG would be the whitepaper that clearly defines the semantic mediation architecture and assesses the opportunities for standardization, rather than an RFP for several not clearly necessary standards.
I see only three areas for interface standardization:
- the form of the reference ontology that is input and presented at the interface between the human knowledge engineer and the reference ontology capturing tool. It is probably a combined graphical and text form, a la UML+OCL, or OWL+RDF.
- the form of the reference ontology that is exported by the capturing tool for use by other tools, including but not limited to the Semantic Mediation Rules tool and the Mediator. It is probably an RDF dialect.
What all is captured here, or can be captured here, has some impact on the capabilities and possible behaviors of the Semantic Mediation Rules tool. So this interface may be an important part of the tool-builder IP. If there were enough experience to know what all might be useful to express, you could get agreement on a standard, even though most tools would only be able to use some of it. Most importantly, however, a standard in this area that is not just a UML profile, or something the like, would require the toolsmith to build some kind of back-end for the off-the-shelf UML or OWL tool that is the primary ontology input tool.
And I would expect that many semantic mediation toolkits might just assume that a UML or OWL tool can be used and will generate the standard XMI or RDF formats.
- the form of mediation rules that is input and presented at the interface between the knowledge engineer and the Semantic Mediation Rules tool. This is an area that is by no means ripe for standardization, because the workings of this tool are very different in various designs. Part of the rules generation process can be automated, and part of it requires human input, and how much is which, and how the automation is enabled, and what algorithms it uses, and how complex the executable rules for the Mediator can be, are all design decisions.
This a primary area of tool-builder IP.
So, IMO, the big question is what the form of the reference ontology is. Do we need a new language for creating them? Do we need a set of RDF additions to OWL, or a UML Profile for Reference Ontologies? If we don't need a new language at all, then we already have all the standards we need, and we need to get some experience with commercial tools.
If we need a new language, then we also need to standardize its export form. A UML profile can be processed by off-the-shelf UML tools and the models can be exported in XMI. Similarly, an RDF add-on to OWL might be supported by an extension to an existing OWL tool and exported as described in OWL/full. (Clark/Parsia are already doing this kind of thing with Pellet.) CLIF may be a desirable export form for some mediation tools, but it is a highly undesirable input form for knowledge engineers working with domain experts. Domain experts can glean most of the content of UML and graphical OWL models with a little experience, but CLIF is about as intelligible as OWL/RDF or XMI or Old Church Slavonic. A wholly new language requires a new set of tools and standards for both ends; a CLIF tool requires a new input form. (One of the failures of OMG SBVR is that it exemplifies a possibly viable input form for rules and definitions that it does not standardize, and then standardizes an output form that merely competes with OCL and CLIF/IKL
-- a new kind of train on existing tracks with no doors for the passengers.)
And at this time in history, I think the standardization of input to the Mediation Rules generator would be a mistake. There is no agreement on how to generate such rules, or even what capabilities of the Mediator they must drive. So, let us by all means have conferences and whitepapers on the subject, but please not as standards development projects.
> The Goverment Linked Open Data WG and the RDB2RDF WG are examples of
> practical things happening in the W3C that will hopefully make some
> real progress possible. More of that kind of thing, perhaps more
> focused at this particular problem, seems like the only practical way
> forward to me.
>
Linked Open Data is the latest in a long line of webheaded information integration technologies, which is in no way related to semantic mediation, as far as I can tell. RDB2RDF is a knowledge-free technical transformation of SQL relational database schemas to RDF Schema + SQL RDF dialect. The object seems to be to allow the implementors of triple-store databases to use real industrial information that is stored in relational data management systems in a predictable way. It is almost the antithesis of semantic mediation, in which the objective is to relate the database-engineered SQL schema to a knowledge-engineered domain ontology. But it is the case that some mediation tools take exactly RDB2RDF approach to the semantic mapping process, and similar projects use XML Schema as the basis. And let us not forget that Cory is working the OMG MOF2RDF standard to make standard RDF export forms for UML models and BPMN models, etc., as RDF Schema + MOF RDF dialect.
This is exactly why W3C is not a better place. I don't think we want semantic integration standards to be strongly influenced by RDB2RDF or Linked Open Data, any more than we want them to be influenced by MOF and SBVR and UML.
I suggest that we can make better progress by getting a whitepaper out there that identifies the architecture, standardizes a component and interface nomenclature, discusses the state of the art in mediation technology and the opportunities for standardization. And I strongly agree that the Ontolog Summit could contribute to the 'state of the art in mediation technology' part, which is critical to the assessment of opportunities for standardization. The AESIG has been so busy trying to generate acceptable RFPs that it has lost sight of its primary value as an Architecture Board SIG -- to provide education on the technology and guidance on the development of a program of work in this area.
-Ed
P.S. In spite of NIST's strong interest in semantic mediation, we (primarily I, no surprise there) have been a thorn in Cory's side since the beginning of the SIMF RFP effort. But I believe the suggestion for a workshop topic for the Ontolog Summit is a much more valuable step, on the way to the whitepaper that would form the basis for any kind of standardization plan, and by-the-by serve as a reference terminology for the emerging papers on the subject. Part of the reason why the EU had 3 different INTEROP projects doing semantic mediation (all differently) is that none of them used the same terms to describe what they were doing.
--
Edward J. Barkmeyer Email: edbark@xxxxxxxx
National Institute of Standards & Technology Manufacturing Systems Integration Division
100 Bureau Drive, Stop 8263 Tel: +1 301-975-3528
Gaithersburg, MD 20899-8263 Cel: +1 240-672-5800
"The opinions expressed above do not reflect consensus of NIST, and have not been reviewed by any Government authority."
> Cheers,
> David
>
> On 10/27/2011 4:33 PM, Cory Casanave wrote:
>
>> Thanks Peter,
>> I have posted a suggestion on the ontology summit page as you suggested. I would also be happy to explore a tread on the topic and have therefor changed the title. The initial message, below, can serve as a problem statement.
>>
>> I would like to point out one clear fact: That with all the great work, tools, research and products available - the problem of information federation still exists and is getting worse. What we have now is either not working or not resonating. We don't need and probably can't produce a 100% solution - we don't have to. Making a 20% improvement in our ability to federate information and exchange data would be of immense benefit to companies, governments and society. I think we can do better than 20% and part of that is accepting that the 100% solutions are not currently practical. We have to make the solution set (of which ontologies are only a part), tractable and practical for widespread adoption - that has not been the track record so far.
>>
>> This is a multi-billion dollar opportunity to address a pervasive and recognized problem. Let's get on with it.
>>
>> Regards,
>> Cory Casanave
>>
>> -----Original Message-----
>> From: peter.yim@xxxxxxxxx [mailto:peter.yim@xxxxxxxxx] On Behalf Of Peter Yim
>> Sent: Wednesday, October 26, 2011 7:00 PM
>> To: Cory Casanave
>> Cc: steve.ray@xxxxxxxxxx; [ontolog-forum]
>> Subject: [OT] process clarification [was - Re: [ontolog-forum] Some Grand Challenge proposal ironies]
>>
>> Cory,
>>
>>
>>
>>> [CoryC] An area of interest to me and many of our clients is solving the information federation problem. ...
>>>
>> [ppy] A good topic indeed. However ...
>>
>> 1. if you are suggesting that folks discuss this "information federation problem" on [ontolog-forum], please consider starting a new thread (with a proper subject line) and move forward from there; or
>>
>> 2. if you are suggesting we (you addressing to Steve, following a remark of his regarding the Ontology Summit indicates that this might have been your purpose), it would be helpful if you condense the proposition to, say, a short theme/title, with a brief (short
>> paragraph) description and post it to the http://ontolog.cim3.net/cgi-bin/wiki.pl?OntologySummit/Suggestions
>> page (like what Christopher has done), and then, via a message post, highlight that suggestions, and take it forward similarly.
>>
>> (That would help allow this thread to stay on point to discuss what Christopher is trying here.)
>>
>>
>> Thanks& regards. =ppy
>>
>
>
>
_________________________________________________________________
Message Archives: http://ontolog.cim3.net/forum/ontolog-forum/
Config Subscr: http://ontolog.cim3.net/mailman/listinfo/ontolog-forum/
Unsubscribe: mailto:ontolog-forum-leave@xxxxxxxxxxxxxxxx
Shared Files: http://ontolog.cim3.net/file/
Community Wiki: http://ontolog.cim3.net/wiki/
To join: http://ontolog.cim3.net/cgi-bin/wiki.pl?WikiHomePage#nid1J