John: (01)
I think we are in agreement, except maybe for the following: (02)
Both a) URIs and b) identifiers under the control of an entity with
special authority (e.g. ISO, DIN, ...) have their pros and cons. (03)
Using b) provides more legal/administrative control that can be used to
maintain the meaning associated with the symbol. In particular, there is
a lot of "old economy" legal power to enforce compliance etc. (04)
URIs, in contrast, have the advantage that they drastically reduce the
cost for the community to look up the intended meaning of the symbol
(i.e. the URI), which reduces the familiarization costs and may support
convergence in the usage of the symbol in communication.
So, IMO, URIs are the best technique that mankind has had so far for
establishing and maintaining / renewing consensus about the meaning of
those identifiers. (05)
Our analysis described in the paper [1] show some quantitative evidence
for that in the case of Wikipedia URIs. (06)
Also, URIs help reduce the delay for establishing consensus, which can
be pretty significant in "old fashioned" standardization procedures. (07)
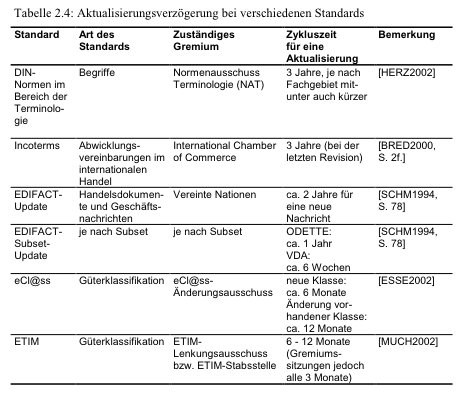
In my PhD thesis, I analyzed the delay of updating standards and the
impact on domain coverage for ontologies. One can show that the delay
causes significant problems when it comes to specific and current
meanings, which are where semantic technology could bring the most
benefit. For example, typical cycle times for updating standards are
between 6 months and several years. That is a lot for domains with
innovation dynamics. (08)
I attach an overview table of the typical standardization delays. (09)
While the thesis was in German, unfortunately, the key findings from
simulation experiments on that problem are described in English in [2]. (010)
I guess we both acknowledge that there are trade-off decisions when
advocating identifiers controlled by a standardization body vs. URIs.
Ideally, both worlds should be integrated as much as possible, e.g.
using wikis for establishing tentative, social symbols and deriving more
thoroughly designed ones with the help of standardization bodies.
Backward links will then support a high degree of interoperability
between both worlds. For me that is similar to the typical publication
stream in academia from poster -> workshop paper -> conference paper ->
journal paper ;-) (011)
Best
Martin (012)
[1] Hepp, Martin; Siorpaes, Katharina; Bachlechner, Daniel: Harvesting
Wiki Consensus: Using Wikipedia Entries as Vocabulary for Knowledge
Management, IEEE Internet Computing, Vol. 11, No. 5, pp. 54-65, Sept-Oct
2007.
Additional data and materials related to this paper are available at a
dedicated Web page: http://www.heppnetz.de/harvesting-wikipedia/ (013)
PDF at
http://www.heppnetz.de/files/hepp-siorpaes-bachlechner-harvesting%20wikipedia%20w5054.pdf (014)
[2] Hepp, Martin: E-Business Vocabularies as a Moving Target:
Quantifying the Conceptual Dynamics in Domains, Proceedings of the 16th
International Conference on Knowledge Engineering and Knowledge
Management (EKAW2008), September 29 - October 3, 2008, Acitrezza, Italy,
Springer LNCS, Vol. 5268, pp. 388-403. (015)
PDF at
http://www.heppnetz.de/files/ConceptualDynamics-EKAW2008-CRC-final6.pdf (016)
John F. Sowa wrote:
> Martin,
>
> We can all agree on two fundamental principles:
>
> 1. The idea of unique identifiers is important.
>
> 2. Providing an automatic method for automatically linking
> those identifiers to official definitions is also important.
>
> But of these two principles, the first is primary, and the
> second is a convenience, which could be satisfied in many
> different ways. The ISO method, for example, is based on
> printed documents: The unique identifier of the document
> together with the unique name within the document is the
> method of resolution. For convenience, the resolution of
> identifiers to definitions could be automated, but the
> printed documents are the official standards.
>
> Kevin's pointer to Tim B-L's note is significant:
>
> http://www.w3.org/DesignIssues/LinkedData.html
>
> That note is dated 2006-07-27, last change: $Date: 2009/06/18 18:24:33 $
> That implies that the note is recent, and it changes often.
>
> In that note, Tim says
>
> > I'll refer to the steps above as rules, but they are expectations
> > of behavior. Breaking them does not destroy anything, but misses
> > an opportunity to make data interconnected. This in turn limits
> > the ways it can later be reused in unexpected ways. It is the
> > unexpected re-use of information which is the value added by the
> > web.
>
> That paragraph that considers those rules as "expectations of
> behavior" raises all kinds of red flags. Whose expectations?
> And whose behavior? Well meaning, but careless programmers?
> Mischievous hackers? Organized terrorists?
>
> Two centuries ago, the standards for units of measurement were
> considered so precious that they were based on platinum exemplars
> kept in sealed vaults in Paris. They were only taken out on rare
> occasions to compare them with other exemplars. For portability,
> the meter was later redefined in terms of a wavelength of light.
>
> But to replace such official standards with documents that could
> be modified by a careless mistake or a mischievous hacker is
> the height of folly.
>
> Unless and until URIs are replaced by or implemented by some
> provably secure mechanisms, I recommend that official standards
> for identifying ontologies and their contents be based methods
> similar to the tried and tested ISO procedures -- not on a
> mechanism as insecure as the W3C URIs.
>
> John Sowa
>
> (017)
--
--------------------------------------------------------------
martin hepp
e-business & web science research group
universitaet der bundeswehr muenchen (018)
e-mail: mhepp@xxxxxxxxxxxx
phone: +49-(0)89-6004-4217
fax: +49-(0)89-6004-4620
www: http://www.unibw.de/ebusiness/ (group)
http://www.heppnetz.de/ (personal)
skype: mfhepp
twitter: mfhepp (019)
Check out the GoodRelations vocabulary for E-Commerce on the Web of Data!
======================================================================== (020)
Webcast:
http://www.heppnetz.de/projects/goodrelations/webcast/ (021)
Talk at the Semantic Technology Conference 2009:
"Semantic Web-based E-Commerce: The GoodRelations Ontology"
http://tinyurl.com/semtech-hepp (022)
Tool for registering your business:
http://www.ebusiness-unibw.org/tools/goodrelations-annotator/ (023)
Overview article on Semantic Universe:
http://tinyurl.com/goodrelations-universe (024)
Project page and resources for developers:
http://purl.org/goodrelations/ (025)
Tutorial materials:
Tutorial at ESWC 2009: The Web of Data for E-Commerce in One Day: A Hands-on
Introduction to the GoodRelations Ontology, RDFa, and Yahoo! SearchMonkey (026)
http://www.ebusiness-unibw.org/wiki/GoodRelations_Tutorial_ESWC2009 (027)
 martin_hepp.vcf
martin_hepp.vcf
Description: Vcard
_________________________________________________________________
Msg Archives: http://ontolog.cim3.net/forum/ontology-summit/
Subscribe/Config: http://ontolog.cim3.net/mailman/listinfo/ontology-summit/
Unsubscribe: mailto:ontology-summit-leave@xxxxxxxxxxxxxxxx
Community Files: http://ontolog.cim3.net/file/work/OntologySummit2009/
Community Wiki: http://ontolog.cim3.net/cgi-bin/wiki.pl?OntologySummit2009
Community Portal: http://ontolog.cim3.net/ (01)
|