John, Jim, Ed, Dave and et al,
I think this thread is going in the wrong direction entirely. It
seems to me that the effort should be focused on the English statements found
in the AsIs database, and the ways in which AsIs users made errors in the
database.
In a recent case, I was able to show that over 40% of the rows in an
actual database had errors of one kind or another in them – and not just
the English statement fields, even the so called structured fields are like
that.
To show that, I had to write a program to extract the actual data in
the database, not just the data fields which happen to be compliant with the
meta data specifications. Often, the entered data is "cleaned"
by the software to meet the specs, but it often isn't the same semantics that
the user entered, and is often clearly semantically different than what user
intended. Users just don’t much care how much sweat the managers, BAs,
SysEs and SWEs have expended on their behalf. They just use it to get
their jobs done with a minimum of attention. Remember that collecting
data is not their major concern – they want the sales to go through no
matter what they have to do to get there.
Reengineering a database (not the code, but the data and data model) is
itself a discovery process that has the usual four lower level processes
running concurrently. These are <Experimenting, Classifying, Observing,
Theorizing>, as shown in the following chart of the sixteen way interactions
among the four processes:
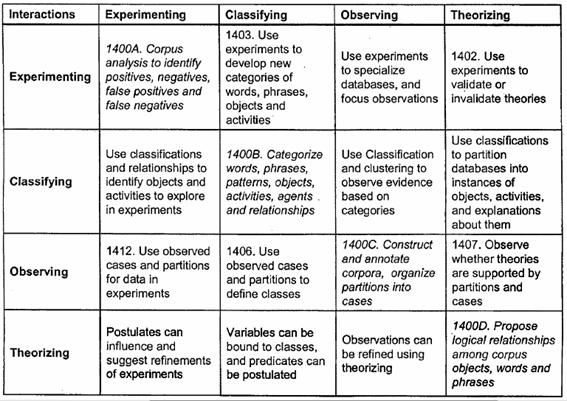
Where each box in the figure begins with a number, that number
correlates to a paragraph or longer description of the interaction for those
two processes in the document at www.englishlogickernel.com/Patent-7-209-923-B1.PDF
The approach described there uses corpus analysis and context modeling to
discover the semantics used in the actual database. Knowing that the
information was perceived in a particular way by each front end user helps the
development architects figure out how to design the ToBe system, and without
it, that information is normally not available to the ToBe system designers.
-Rich
Sincerely,
Rich Cooper
EnglishLogicKernel.com
Rich AT EnglishLogicKernel DOT com
9 4 9 \ 5 2 5 - 5 7 1 2
-----Original Message-----
From: ontolog-forum-bounces@xxxxxxxxxxxxxxxx
[mailto:ontolog-forum-bounces@xxxxxxxxxxxxxxxx] On Behalf Of John F. Sowa
Sent: Tuesday, September 14, 2010 5:50 PM
To: ontolog-forum@xxxxxxxxxxxxxxxx
Cc: Ken Orr; Arun Majumdar
Subject: Re: [ontolog-forum] Language vs Logic
Jim, Ed, Dave, and Rich,
I completely agree with what you say below But I will add that
proper tools can make *many orders of magnitude* improvement --
e.g., going from 80 person years of tedious work to 15 person weeks
of more exciting stuff.
I realize that you're not going to believe what I say below, but you
can verify it by asking Ed Yourdon. He did the initial consulting
before recommending Arun Majumdar and Andre Leclerc for a short
study project, which ended up in delivering exactly what a major
consulting firm claimed would take 80 person-years by the hand
methods that you describe.
Another person who is familiar with the project and all parties
involved is Ken Orr (on cc list above).
JR>> This is OK as long as you realize that data integrity and
data
semantics are
>> contained in the applications, that you understand these
legacy systems well
>> enough to be sure you understand the data semantics and that
you can
>> reproduce them without error. Legacy databases are often full
of codes that
>> are meaningless except when interpreted by the applications.
EB> Strongly agree. Reverse engineering a "legacy"
(read: existing/useful)
> database can be an intensely manual process. Analysis of the
> application code can tell you what a data element is used for and
how it
> is used/interpreted. The database schema itself can only
give you a
> name, a key set, and a datatype. OK, SQL2 allows you to add
a lot of
> rules about data element relationships, and presumably the ones
that are
> actually written in the schema have some conceptual basis.
I also agree. But it is possible to analyze the executable code
and
compare it to *all* the English (or other NL) documentation -- that
includes specifications, requirements documents, manuals, emails,
rough notes, and transcriptions of oral remarks by users, managers,
programmers, etc.
For a brief summary of the requirements by the customer, the method
by which Arun and Andre conducted the "study", and the
results,
stored on one CD-ROM, which were exactly what the customer wanted,
see slides 91 to 98 of the following:
http://www.jfsowa.com/talks/iss.pdf
Just type "91" into the Adobe counter at the bottom of the
screen
to go straight to those slides.
EB> Reverse engineering a database is the process of converting a
data
> structure model back into the concept model that it
implements. And the
> problem is that the "forward engineering" mapping is not
one to one from
> modeling_language_ to implementation_language_. It is
many-to-one,
> which means that a simple inversion rule is wrong much of the
time, and
> the total effect of the simple rules on an interesting database
schema
> is always to produce nonsense. Application analysis has the
advantage
> of context in each element interpretation; database schema
analysis is
> exceedingly limited in that regard.
That is part of the job, but it doesn't solve the problem of 40 years
of legacy code with numerous patches and outdated documentation.
The customer's problem was (1) to *verify* the mapping between
documentation and implementation and report all discrepancies
(or at least as many a could be found), (2) to build a glossary of
all the English terminology with cross references to all the changes
over the years, (3) to build a data dictionary with a specification
that corresponded to the implementation, not to the obsolete
documentation, and (4) to cross reference all the English terms
with all the programming and database terms and all the changes
over the years.
EB> That said, other contextual knowledge can be brought to
bear. If, for
> example, you know that the database design followed some
"information
> analysis method" and the database schema was then
"generated"...
Good luck when some of the programs predated any kind of
"methods",
other documentation was lost years ago, and the people who wrote
or patched the code retired, died, moved on, or just forgot.
EB> So, if you know the design method and believe it was used
consistently
> and faithfully, you can code a reverse mapping that is complex but
> fairly reliable, but you still have to have human engineers
looking over
> every detail and repairing the weird things....
Arun and Andre were the two engineers who checked anything that the
computer couldn't resolve automatically. And the computer did
indeed
discover a lot of weird stuff. Look at slides 95 to 97 for a tiny
sample of weird.
But as they continued with the analysis, Arun and Andre found that
the computer's estimate of how certain it was about any conclusion
was usually right. They raised the threshold, so that the
computer
wouldn't ring a bell to alert them unless it was really uncertain
about some point.
DMcD> Most of the legacy systems we see were forward engineered once
upon
> a time, but then modified in place, without going through the
original
> model to design to code process. So you have a mix of things
that can
> be faithfully reverse engineered mixed in with things that just
got bolted on.
Yes. And when the code is up to 40 years old, there are a lot of
ad hoc bolts. That's why the big consulting firm estimated that
it
would require 80 person-years to do the job. But Arun and Andre
did it in 15 person-weeks (while the computer worked 24/7).
RC> Personally, I have found that most AsIs DBs are useful histories
> of how people reacted to the expressed interfaces. The code,
which
> is supposed to interpret the fields, is often not consistent with
> the way people used the database.
That's true. That's why you need to relate the implementation
to *all* the documentation by users of every kind as well as
by managers and programmers of every kind. They all have
different views of the system, and it's essential to correlate
all their documents and cross reference them to each other and
to the actual implementation.
EB> Yes, you can be stuck with maintenance programmers and ignorant
> users. But that means you are genuinely flying blind with
respect
> to the actual data content and intent...
Yes, that's why the customer asked the consulting firm to analyze
all their software and all their documentation. When that
estimate
was too high, they asked Ed Yourdon for a second opinion, and he
called in Arun and Andre. They delivered a solution that
gave
the customer everything that the big firm claimed that they would
require 80 person-years to do.
Please read the slides. And as I said, you don't have to take
my word for it. There is also a Cutter Consortium technical
report written by Andre and Arun. Ask Arun for a copy. But
it doesn't say as much about the NLP technology as I wrote
on the iss.pdf slides.
John
_________________________________________________________________
Message Archives: http://ontolog.cim3.net/forum/ontolog-forum/
Config Subscr:
http://ontolog.cim3.net/mailman/listinfo/ontolog-forum/
Unsubscribe: mailto:ontolog-forum-leave@xxxxxxxxxxxxxxxx
Shared Files: http://ontolog.cim3.net/file/
Community Wiki: http://ontolog.cim3.net/wiki/
To join: http://ontolog.cim3.net/cgi-bin/wiki.pl?WikiHomePage#nid1J
To Post: mailto:ontolog-forum@xxxxxxxxxxxxxxxx