Dear John,
You wrote:
RC
> Actually, rules can
be stored in relational DBs also, not just facts.
You can store anything in
any DB, if you treat it as an uninterpreted "blob" (Binary Large
Object). The critical distinction is how and whether those rules are used
in reasoning.
While BLOBs are widely used to store unstructured
quantitative data such as EKG signals, documents, and such other byte arrays in
a DB cell, that isn’t what I was referring to. BLOBs are useful when the
data can be inserted, queried or deleted in one hunk without further semantic interpretation
by the DBMS. Applications interpret each BLOB based on what the
programmer “knows” the BLOB implements.
Consider a parsed rule which parse produces a graph of
the syntax of the rule. Think of the way algebraic parsers operate. The
parse output consists of triples: one operator and two objects that participate
in the operation of that triple. Allocate one node in the graph for each
of the three elements, with the operator at the top node and two arcs leaving
said top node toward the two objects. Store the graph in two tables
called Nodes and Arcs.
For parameterized function calls such as f(x,y), the
parse produces arcs which are labeled with the parameterization term. For
example, consider the simple equation:
f(x,y) = x + y
which can be drawn in graph form as:
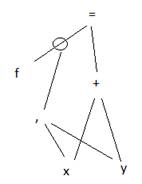
Whereas a BLOB could also be used, the above
representation lets the programmer store the triples in Nodes and Arcs rows
where they can be more easily programmed to traverse the graph.
I use a different <Node, Arc> design for the
triple graph from that I use for the search forest. Searching the graph constructs
the forest, and leads to the AND/OR structuring I’ve mentioned many times in
past posts. The solution subtree is the embedded tree with max value, min
cost, or whatever criterion is used for choosing the preferred solution
subtree.
-Rich
Sincerely,
Rich Cooper
EnglishLogicKernel.com
Rich AT EnglishLogicKernel DOT com
9 4 9 \ 5 2 5 - 5 7 1 2
-----Original Message-----
From: ontolog-forum-bounces@xxxxxxxxxxxxxxxx
[mailto:ontolog-forum-bounces@xxxxxxxxxxxxxxxx] On Behalf Of John F Sowa
Sent: Friday, August 10, 2012 9:11 AM
To: '[ontolog-forum] '
Subject: Re: [ontolog-forum] Ontologies,
knowledge model, knowledge base
Doug and Rich,
In general, I agree that Cyc has a good metalevel
terminology and
methodology for knowledge engineering. But I
would cite the warning
by Alan Perlis: You can't translate informal
language to formal
language by any formal algorithm. There are many
"judgment calls"
that cannot be stated in hard-and-fast rules.
DF
> At Cycorp... We considered an ontology to define
terms, properties
> of terms, and theories about the terms, while a
knowledge base was
> like a database, using terms defined and provided
rules in the ontology
> to describe information about individuals in some
domain of concern.
I agree that's a good distinction. But the
dividing line between what
should be in the definitions and what should be in the
"background
knowledge" is often fuzzy.
Many people let their tools make the
distinction: if it can be
stated in OWL, it's ontology; anything else goes in
the knowledge
base or database. But that distinction is
unreliable.
For example, Plato cited a definition of Human as
'animal with speech'
or 'featherless biped'. Either one could be
represented in OWL,
but the first is preferred because it is *essential*,
but the other
is *accidental*. However, many people -- Quine
is a prime example --
maintain that there are no clear criteria for making
that distinction.
DF
> Vocabulary microtheories, Theory microtheories,
and Data microtheories.
That's also a good distinction. But there are
many vocabulary terms
that are also technical terms in some theory.
For example, the words
'force', 'energy', and 'mass' are common vocabulary
terms that became
technical terms in physics.
When you have multiple microtheories that use the same
technical terms,
you also run into issues about using values defined in
different ways
in different microtheories. That can become
critical for a large
engineering project that uses different microtheories
to specify
different kinds of components.
DF
> This term [knowledge model] was not used at
Cycorp while i was there.
I agree that it's rare, and I would avoid it.
RC
> Actually, rules can be stored in relational DBs
also, not just facts.
You can store anything in any DB, if you treat it as
an uninterpreted
"blob" (Binary Large Object). The
critical distinction is how and
whether those rules are used in reasoning.
In SQL, there are three kinds of "knowledge"
that can be used to
supplement the database: *views*, which are
backward-chaining rules;
*constraints*, which block illegal updates; and
*triggers*, which
are forward-chaining rules that invoke operations
during updates.
If you use those features extensively, they would make
SQL into
a kind of deductive database that could be called a
knowledge base.
This is an issue that many DB and AI people have been
discussing
since the 1970s -- that includes Ted Codd, who was not
happy with
the quirks and limitations of the SQL design and
implementation.
RC
> In your tutorial, on slide 9, you state:
>
> We need better tools, interfaces, and
methodologies:
> ● Experts in any field spend
years to become experts.
> ● They don’t have time to learn
complex tools and notations.
> ● The ideal amount of training
time is ZERO.
> ● Subject-matter experts should
do productive work on day 1.
>
> The gist of that bullet list is that people
should all learn one
> ontology language/toolset/methodology.
No, definitely not! What I was trying to say is
that future systems
should support *everybody's* favorite ontology and
notation. When
I said "zero training time", I meant that
nobody should be required
to learn a notation or a vocabulary that is different
from whatever
terms, diagrams, and notations they prefer for their
daily work.
> The knowledge that SMEs develop is strictly in
the application domain,
> and almost never in any theoretical area other
than the usual minor
> amount of math, physics, chemistry or other more
generalized knowledge.
I agree with that principle. My only
disagreement is in the claim
that applications don't involve theory. I use
the word 'theoretical'
for *every* kind of "book learning'. That
includes all knowledge
that is represented in words or symbols of any kind.
John
_________________________________________________________________
Message Archives:
http://ontolog.cim3.net/forum/ontolog-forum/
Config Subscr: http://ontolog.cim3.net/mailman/listinfo/ontolog-forum/
Unsubscribe:
mailto:ontolog-forum-leave@xxxxxxxxxxxxxxxx
Shared Files: http://ontolog.cim3.net/file/
Community Wiki: http://ontolog.cim3.net/wiki/
To join:
http://ontolog.cim3.net/cgi-bin/wiki.pl?WikiHomePage#nid1J