|
Hello,
During our last phone conference we described one of the
major objectives is to provide better Search features based on Taxo-Thesaurus
model of the Wiki (and the explicit Body of Knowledge contained or referenced
there).
Denise has developed a detailed inventory of the Wiki, and
is preparing to extract concepts for further refinement.
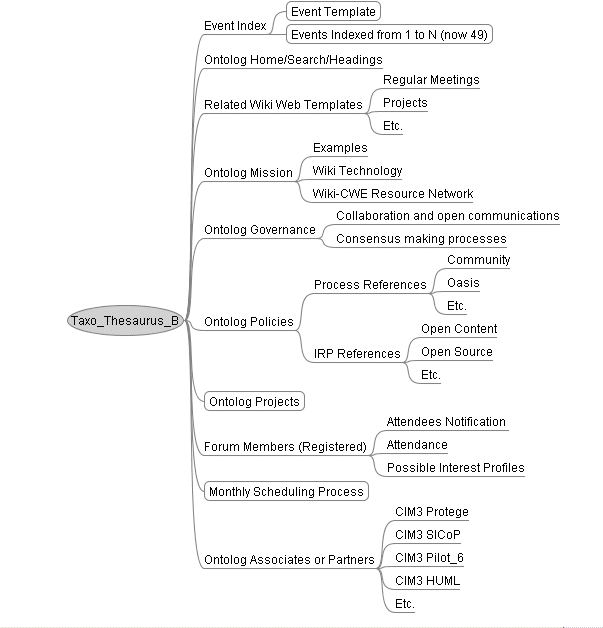
As an intermediate step, I developed a simple Tree
representing the wiki as it appears to me. The free application is called
FreeMind, and is very simple to use to construct a visual map of
content.
I believe we have a treasure of useful and usable knowledge
about many domains available in documents and PPT slide pages. Concept
extraction and refinements along with maps, should prove valuable to members of
some communities.
Denise's slides, and the other slides and discussions from
the two earlier Ontologizing sessions include questions we need to ask about the
context, user needs, and sense-making opportunities.
This Thursday's Ontolog session seems to be an opportunity
to consider next steps in more detail, and seek answers to the questions we
posed to ourselves earlier.
Comments? Questions?
Regards,
Bob Smith,
Tall Tree Labs
Huntington Beach, CA
714 536 1084 From: ontologizing-bounces@xxxxxxxxxxxxxxxx [mailto:ontologizing-bounces@xxxxxxxxxxxxxxxx] On Behalf Of dbedford@xxxxxxxxxxxxx Sent: Sunday, May 21, 2006 4:26 PM To: Ontologizing-Ontolog Cc: 'Ontologizing-Ontolog'; Patrick Heinig Subject: RE: [ontologizing] Re: [TaxoThesaurus] Ontolog Wiki Inventory - time Yes, let's chat via email. We have an internal IT conference Monday - Thursday this week so I will be in and out. I have to chat with one of our programmers to see if there is an open source crawler that can capture the content and then process it. We were putting together this approach to generate metadata for our news feeds - using the Oracle crawler + Teragram. Best regards, Denise
_________________________________________________________________ Msg Archives: http://ontolog.cim3.net/forum/ontologizing/ Subscribe/Unsubscribe/Config: http://ontolog.cim3.net/mailman/listinfo/ontologizing/ Community Portal: http://ontolog.cim3.net/ Community Files: http://ontolog.cim3.net/file/work/OntologizingOntolog/ Community Wiki: http://ontolog.cim3.net/cgi-bin/wiki.pl?OntologizingOntolog (01) |
{kind=link}