Here is the image from the study which
shows how the points cluster:
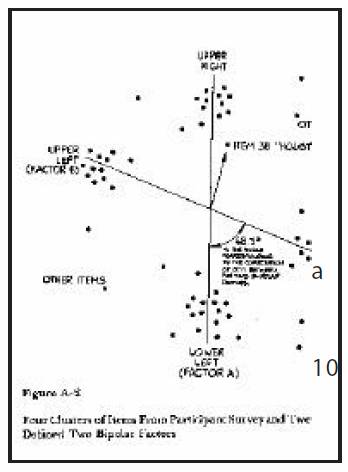
You can notice groups of points to call a
cluster, which is equivalent to using FCA methods on, in this case, numeric score
data.
T-Rich
Sincerely,
Rich Cooper
EnglishLogicKernel.com
Rich AT EnglishLogicKernel DOT com
9 4 9 \ 5 2 5 - 5 7 1 2
From:
ontolog-forum-bounces@xxxxxxxxxxxxxxxx
[mailto:ontolog-forum-bounces@xxxxxxxxxxxxxxxx] On Behalf Of Rich Cooper
Sent: Friday, November 05, 2010
8:57 PM
To: '[ontolog-forum] '
Subject: [ontolog-forum] Polysemy
and Subjectivity in Ontolgies - theHDBIexample
I'm interested in constructing ontologies from that initial condition
of only measured data, not rules and relationships just yet (later in the
ontology's development, we will add rules and relationships, but not just yet).
Call this ontology O0. Initially it has a set of samples, and each
one can be accessed by the identifiers O0[1] through O0[O0.count] if that
notation is acceptable to you.
Here is a quote from this type of research, which is rather typical of
medical databases being KAed:
Such a balanced data base with weighted and resealed
scores would also support a variety of cross tabulation studies to show the
joint occurrence of different preferences or avoidances in a balanced sample
reflective of the larger population. Generalizability studies to different
cultures would require a data base appropriate to each culture.
Here is the study from which this quote came, if you are interested in
deeper context:
http://www.hbdi.com/uploads/100021_resources/100331.pdf
Rather than starting with predefined classes, users started with a
database of numerical data scores, and then had observers rank the observed facts,
which relate to personality inventories of various measures which account for
subjective differences among a large number of people - 439 in some of these
factors.
Then they applied a theory - the HDBI study checked validity of the
theory's various classes (A, B, C and D) in a multidimensional space and found
four prominent clusters, together with a fairly small fifth group (highly
distributed) of other samples - the outliers.
The study deals with individual differences of the people in the sample
measurements, and how the sample population fits into the various clusters.
I think it could illuminate any discussion we might want to have on
subjective factors in ontologies, on how ontologies are perceived, and on how
they can be constructed from real data.
Is anyone interested? Please read the study if you can, though
you might want to post while reading it as well.
Thanks,
-Rich
Sincerely,
Rich Cooper
EnglishLogicKernel.com
Rich AT EnglishLogicKernel DOT com
9 4 9 \ 5 2 5 - 5 7 1 2