Hi Joel,
Thanks for your interest. My comments are embedded below,
-Rich
Sincerely,
Rich Cooper
EnglishLogicKernel.com
Rich AT EnglishLogicKernel DOT com
9 4 9 \ 5 2 5 - 5 7 1 2
-----Original Message-----
From: ontolog-forum-bounces@xxxxxxxxxxxxxxxx
[mailto:ontolog-forum-bounces@xxxxxxxxxxxxxxxx] On Behalf Of Joel Bender
Sent: Monday, July 19, 2010 10:52 AM
To: [ontolog-forum]
Subject: Re: [ontolog-forum] Interactions (was: SemRepositories)
Rich,
> I consider the following figure a useful tool for
managing semantic discovery projects...
Why is this not diagonally symmetric? What's the
distinction between (Experimenting, Classifying) and (Classifying,
Experimenting)?
Joel
Looking at just the four boxes for those
two processes:
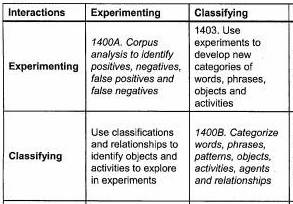
Suppose you are trying to experiment with
classes of words that indicate transfer of liquids, like “leak”, “flow”,
“slosh”, “pour” and so forth. You would like to organize
those liquid-transfer verbs into subclasses which work well with a specific
corpus. In cell 1400B (the diagonal), the goal is to categorize the verbs
by semantic meaning, by the signatures of syntactic forms in which they occur,
and/or by correlations of each instantiated verb’s meaning (assigned by
the interpreter) and its designated subjects, objects and adverbs.
The Experimenting diagonal cell 1400A
indicates that the goal is to identify sentences in which the instantiated verb
is/isn’t used in accord with the classification of liquid-transfer verbs
from 1400B.
Perhaps you want to write an English interpreter
(an English Logic Kernel – ELK) for a specific corpus. You develop
a procedure(s) for each sentence that interprets each verb, and a procedure(s)
for each word, phrase, sentence, object, modifier and other parts of speech
that you can consider consistent with the meaning of the corpus. This
approach helps organize your discovery processes and form them into a managed
project leading to a planned result.
Is that any clearer?
You may also want to read the following:
www.englishlogickernel.com\Patent-7-209-923-B1.PDF
That document explains in deeper detail,
though it is intended for an audience of programmers and linguists, implementers
of the ideas described there.
HTH,
-Rich